
"It's incredibly easy to write code. It's incredibly hard to read code."
As a developer, you know that reading code is a muscle memory one develops. You see patterns, a multitude of braces and curly brackets, and know immediately where functions begin and end. Syntax highlighting immediately tells you what the tokens, identifiers, and keywords are. Any time you work with code - in any language - you come to expect this structure and enrichment.
And then you share your code with your hackathon group, your colleagues, or post it online, and...wait, what's this? The code you just copy-pasted into your text editor or group chat is indistinguishable from the plaintext? The lengthy dev log you're posting on your site has no code structuring, class styling, or syntax highlighting?
Sure, you could painstakingly tack on tab spacing and ad hoc styling for every code snippet you share, or - if you're lucky and can use embeds - use GitHub Gists instead of pasting code directly from the IDE. But these workarounds are infeasible, and scale incredibly poorly.
Work smarter, not harder, and use Code Detection, Runtime's Technical Language Processing (TLP) based API. Detecting code within unstructured text, and presenting it as dev-readable code - properly formatted, syntax highlighted, and easily searchable/indexable - out-of-the-box, with no human assistance required. Perfect for anything you can think of: messaging apps, note-taking apps and dev collaboration tools, code editors, and blogs/publications.
Technical Language Processing: NLP For Engineering Data
Natural Language Processing (NLP), is a branch of AI/ML concerned with programming computers to automatically detect, process, and analyze human languages in a myriad of ways. Speech recognition-enabled "smart assistants" in your phones, for example. Or Language Modeling to help you type - via swiping, autocorrect, or word prediction.
But what happens when you scale up conventional NLP tools in specific industrial use-cases? Say, for example, an API marketplace scanning endpoint descriptions numbering in the hundreds of thousands sitewide, then summarizing and auto-generating documentation, tags, and similarity scores for its recommendation engines?

As awesome as they are, NLPs as-is cannot serve our inherently technical needs, the more specific those needs become.
Even within just the scope of this article in software development, there will always be a disconnect between engineering requirements and what consumer-orientated NLP tools can provide, because conventional NLP tools were not designed for technical text in ways that are aware of the needs of development, internal metrics, and business logic.
That's where Technical Language Processing, or TLP, comes in.
Code Detection is the first in a class of Technical Language Processing APIs powered by Runtime. Runtime's TLP based approaches are developed with the use-cases of the IT industry in mind. They are highly specific NLPs trained with strict acceptance criteria, on millions of source code files, with iterative development driving every step of the process.
The Detect-Classify-Prettify Cycle
The Code Detection API is a full end-to-end pipeline. You copy-paste code snippets directly from your dev environment to your rich-text environment, and get back language-classified, properly formatted, structured, and syntax highlighted ('prettified') code. Let's look at an example use-case.
Step 1
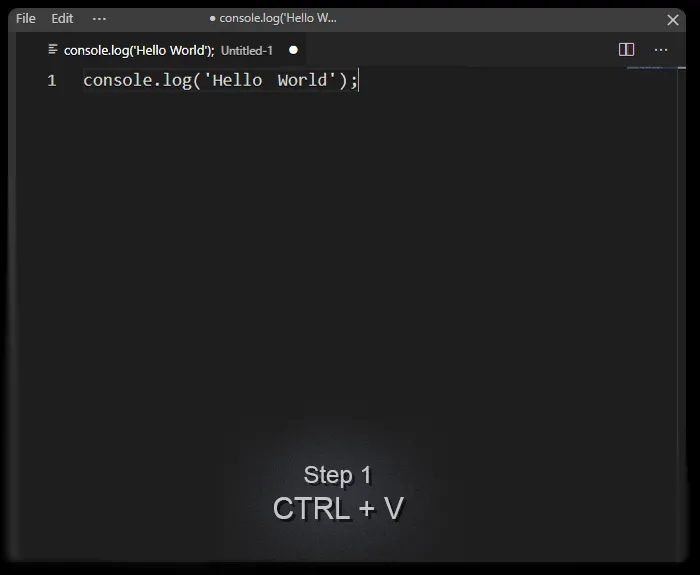
You paste a block of text containing code snippets into your app. This could be the group channel in your messaging app, collaboration platform, notes app, code editor, your website's blog - it doesn't matter. The Code Detection API uses complex machine learning algorithms under the hood, but as far as you're concerned it is only a conventional API operating on the Request/Response cycle, and is therefore client agnostic.
Step 2
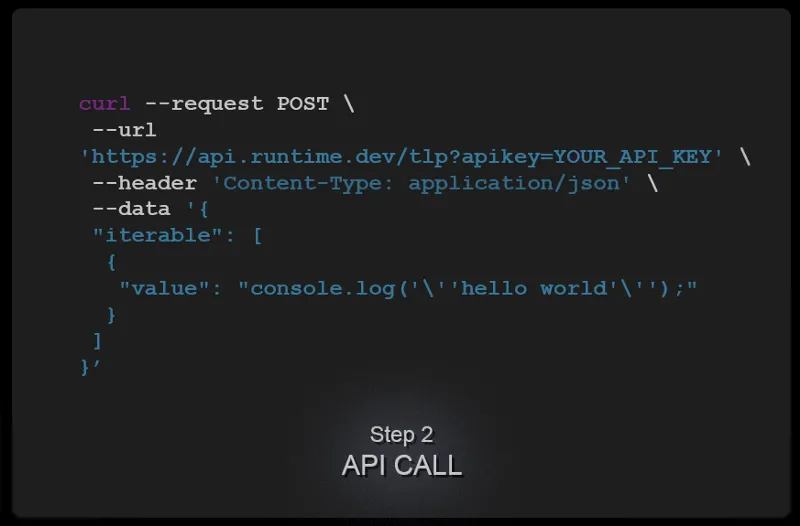
In response to the clipboard operation, your app makes a Code Detection API call over HTTP, via the POST verb, with the code snippet in question included as data payload. Over at its servers, Code Detection's algorithms extract and classify valid code within the unstructured text, annotating the tokens using external information (Named Entity Recognition, or NER), preprocessing, applying state-of-the-art pre-trained models, and parsing the results into structured, formatted data ready for you to use.
Step 3
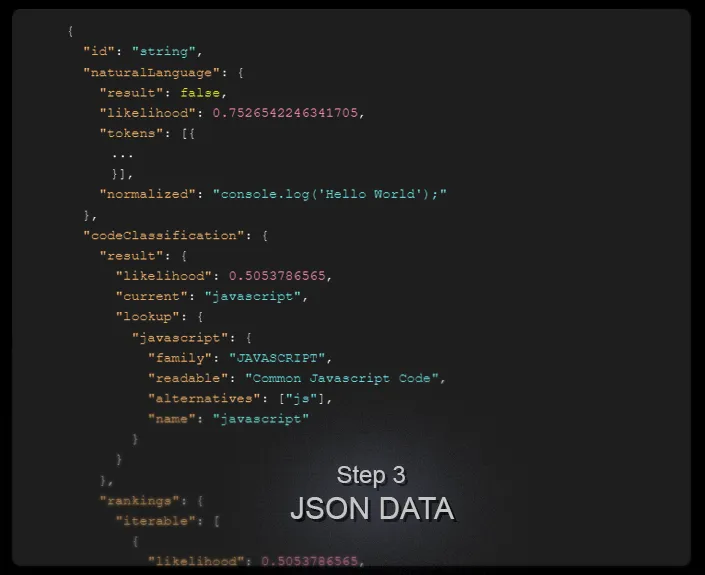
You get back well-structured, self-documenting JSON data, telling you if your block of text contained valid code (vs. plaintext/natural language), and if so, results of code classification (i.e. the language it likely belongs to, sorted by probability), and of course, properly structured and formatted code with optional features (like truncation or generated tags) to boot.
At no point in this process does the Code Detection API need you to include entire files from your project or internal documentation, nor does it need to know your file extensions or any kind of proprietary data. Your codebase remains entirely secure.
Teams. Not "Rockstar Developers".
You can already see why the Code Detection API would be great as a pluggable tool in IDEs and text editors, or dev blogs and web publications, but considering trends in modern software development there's another equally critical need - efficient, scalable collaboration.
In a world where developers work together and share results for collective knowledge, frequently exchanging code snippets in messaging and productivity apps (i.e. anything outside a conventional dev environment), developers will find using Machine Learning techniques in an effort to streamline intra/inter-team communication to be incredibly useful.
Collaboration is increasingly relevant as modern development trends towards microservices architectures - hundreds of different teams working on their own autonomous services that are also part of a larger ecosystem - that need to exchange data and work together. Streamlined collaboration could mean the difference between coming together and overcoming unforeseen platform or technology constraints, and missed deadlines that set your release dates back by weeks or even months.
Pricing
Runtime's Code Detection API offers packages tailor-made for app developers as well as AI and Machine Learning researchers, and starting at as low as $14.99 per month you get natural language vs. technical language (code) detection, programming language classification, and of course, well-formatted, syntax-highlighted code as output. Also available are tiered packages offering detailed confidence metrics, tag generation, and user bias support for more accurate results. Custom pricing is also available on contact.
Conclusion
Runtime's Code Detection API can work with any programming language, and since it is always learning from unlabeled source code, it will only get better, support more languages, and be more accurate with time. It handles even those languages human programmers might miss because of obscurity or being out of vogue, and keeps collaboration flowing smoothly without any holdups or ambiguity.
Runtime's TLP-based approach served up to devs on a platter as a simple end-to-end API pipeline, cuts down on the need for external tools and plugins, any proprietary IDE, or systematic human review, saving countless hours of development resources and improving dev collaboration and code quality at scale.
Comments
Loading comments…