
Introduction
As per a 2023 report, global retail e-commerce sales were expected to undergo a 39% growth in the coming years. To thrive in this competitive arena, staying ahead with cutting-edge technology is key. Data scraping has, for some time now, been the go-to option for e-commerce, enabling companies to extract valuable data --- market trends, competitor pricing, and consumer behavior. Such scraped data empowers informed decision-making, giving businesses a competitive edge.
Yet, manually implementing a web scraping process that scales comes with its own set of challenges like complex coding, scripts breaking due to website changes, and a multitude of anti-scraping measures to overcome.
This is where a no-code data scraper can help. These are essentially tools with highly user-friendly and intuitive interfaces that help you collect the data you need without having to write a single line of code, while also being managed services that adapt to website changes.
In this article, we'll show you how to scrape product details from Amazon using such a powerful no-code scraping tool. Whether you're a marketer, small business owner, or just curious about data extraction --- we have you covered.
Before we get to that though, let's quickly discuss the benefits of scraping Amazon's data, its legality, and the challenges involved.
What are the benefits of scraping Amazon?
Amazon is a vast e-commerce marketplace with millions of products and customers, and extracting data from it can provide valuable insights for both individuals and corporations.
Here's a breakdown:
- Price Monitoring: As an individual, you could leverage web scraping to find cheap deals As a business, continuous price monitoring and adjustment helps you stay competitive and attract more customers.
- Market research: Analyzing product details, including descriptions, reviews, and ratings helps you understand market trends, consumer preferences, and gaps in the market.
- Keyword analysis: Scraping product names from Amazon helps identify the terms potential customers use to find similar products as well as the most popular keywords associated with your product.
- Competitor analysis: Scraping competitor products allows you to benchmark their offerings against yours, identify strengths and weaknesses, and develop strategies that outperform competitors.
- Product development: Insights from customer reviews and ratings can guide product improvement and innovation, helping you better meet customer needs.
In short, scraping Amazon provides a competitive edge through continuous access to valuable, actionable data.
Is it legal to scrape Amazon?
Generally speaking, it is perfectly legal to scrape publicly available data on the internet. Amazon's public product listings and information are freely accessible, and scraping this data doesn't violate their terms of service.
Remember: avoid excessive requests, and never scrape data behind a login, personal information, or sensitive data. This is illegal and against Amazon's rules.
💡 You can find out more here:
Is web scraping via Octoparse legal and ethical? | Help Center
*Web scraping and crawling aren't illegal by themselves unless people use them for harmful activities, such as...*helpcenter.octoparse.com
However, besides legal and ethical issues, scraping Amazon also involves other challenges.
Challenges of Scraping Amazon for Product Details:
Scraping Amazon for product details presents several challenges:
- Amazon is a complex website and requires significant development effort. This is a bottleneck if you don't have a technical background.
- Even if you can get past that, page layout changes will break your scraping scripts based on CSS/XPath selectors. When Amazon updates their page, the paths to these elements will change.
- IP blocking and rate limiting. Amazon blocks IPs that make too many requests and restricts the number of requests within a certain timeframe.
- CAPTCHA, JavaScript-based challenges, and User Agent blacklisting are designed to block bots --- and pose significant hurdles.
But fear not. Octoparse is a no-code free web scraper with templates for scraping Amazon search results, product detail pages, reviews, and more --- that is constantly kept up to date. It adapts to changing layouts, is able to bypass IP blocks using built-in proxy management and managing request rates for you, and can even auto-bypass blocking mechanisms like CAPTCHAs and Cloudflare protection --- all while following major data protection laws, and staying compliant with Amazon's TOS.
Scraping Amazon Using Octoparse
What is Octoparse?
Octoparse is a powerful, no-code web scraping tool designed to simplify data extraction for everyone, regardless of technical skill level.
With its user-friendly point-and-click interface, Octoparse lets you visually select the data you want from any page, and it'll go and scrape this data for you --- no need for any programming skills.
Some of its key features include:
- A visual workflow designer that lets you create and manage scraping workflow visually.
- Pre-configured templates that let you start scraping immediately with templates for popular sites like Amazon.
- Automation and cloud service that lets you schedule scrapes and automate data export with 24/7 cloud support.
- Provides advanced capabilities to handle IP rotation, CAPTCHA solving, proxies, and more.
With these features, you can seamlessly extract Amazon product data and export it to a format of your choice (JSON, CSV, XML), which you can then analyze to derive important insights that can help you.
Now, there are mainly two ways in which you can use Octoparse to scrape Amazon. The fastest, best option is to use Octoparse's Amazon-specific templates (covering many regions and ranging from search results to product detail pages and reviews).
Or, if they don't have the specific template you want, you could always use the app to scrape a specific URL, setting up the task flow yourself by pointing and selecting the specific data you need.
👉 You can check out all their templates here:
Octoparse Templates - Extract Data Easily Online
*Browse hundreds of preset web scraping templates for the most popular websites and get data instantly with zero setup.*www.octoparse.com
For the purpose of this guide, we'll be using Octoparse's Amazon product scraper (by keywords) template.
Step-by-step guide to scraping Amazon using Octoparse Templates
Step 1: Set up an account and download the Octoparse app for desktop (Windows)
- First, go to the Octoparse website and create an account if you don't already have one. Then, download the Octoparse app for desktop (Windows, for this guide) from here and launch the app, signing in when prompted.
Step 2: Configure a new task and commence data extraction
- When you launch the app, it should bring you to this dashboard.
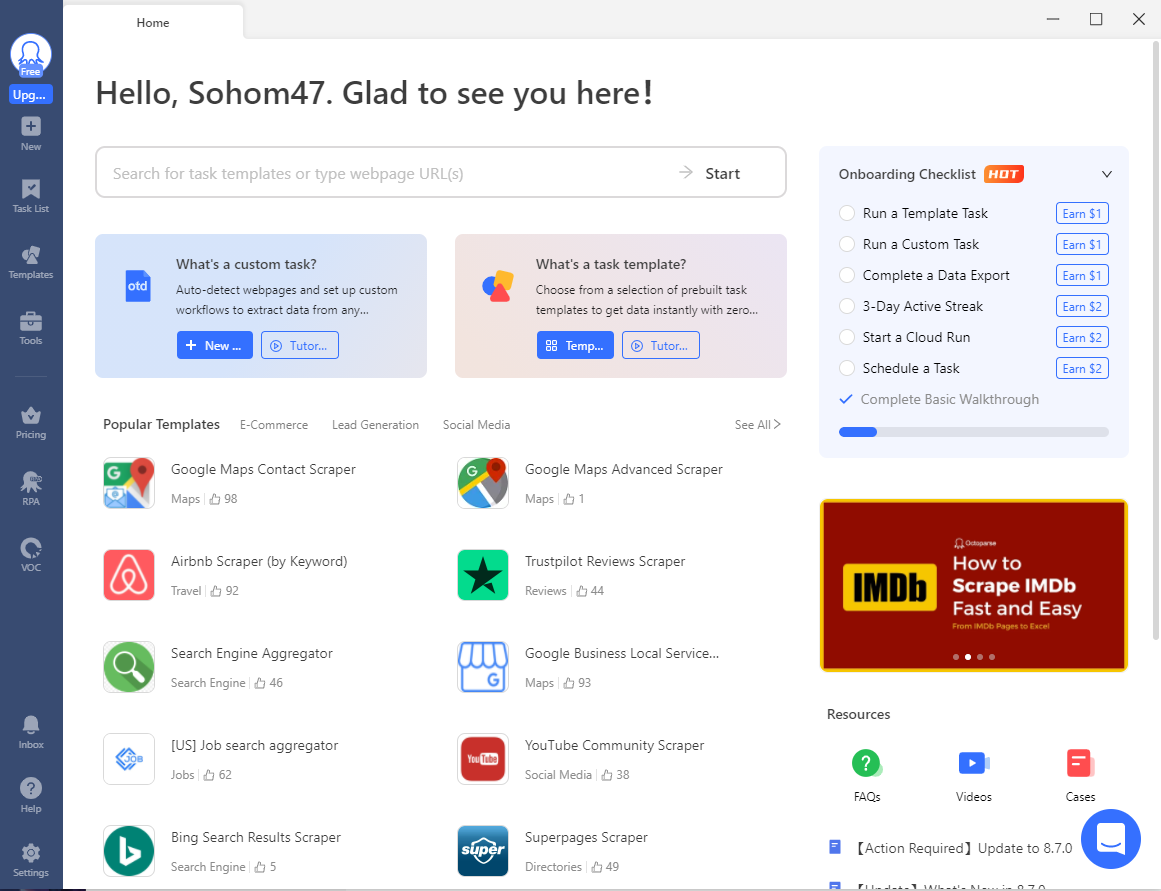
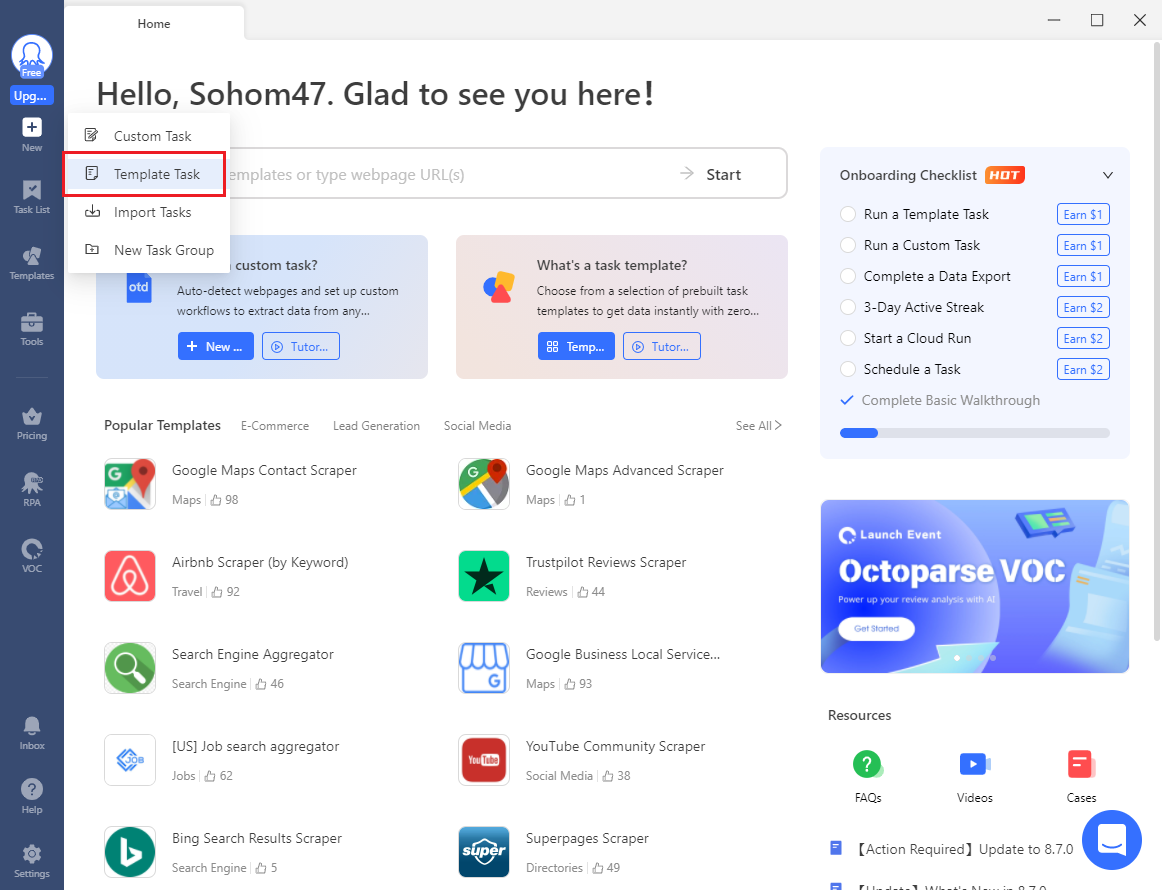
- Next, click on 'New Task' and select 'Template Task' from the dropdown.
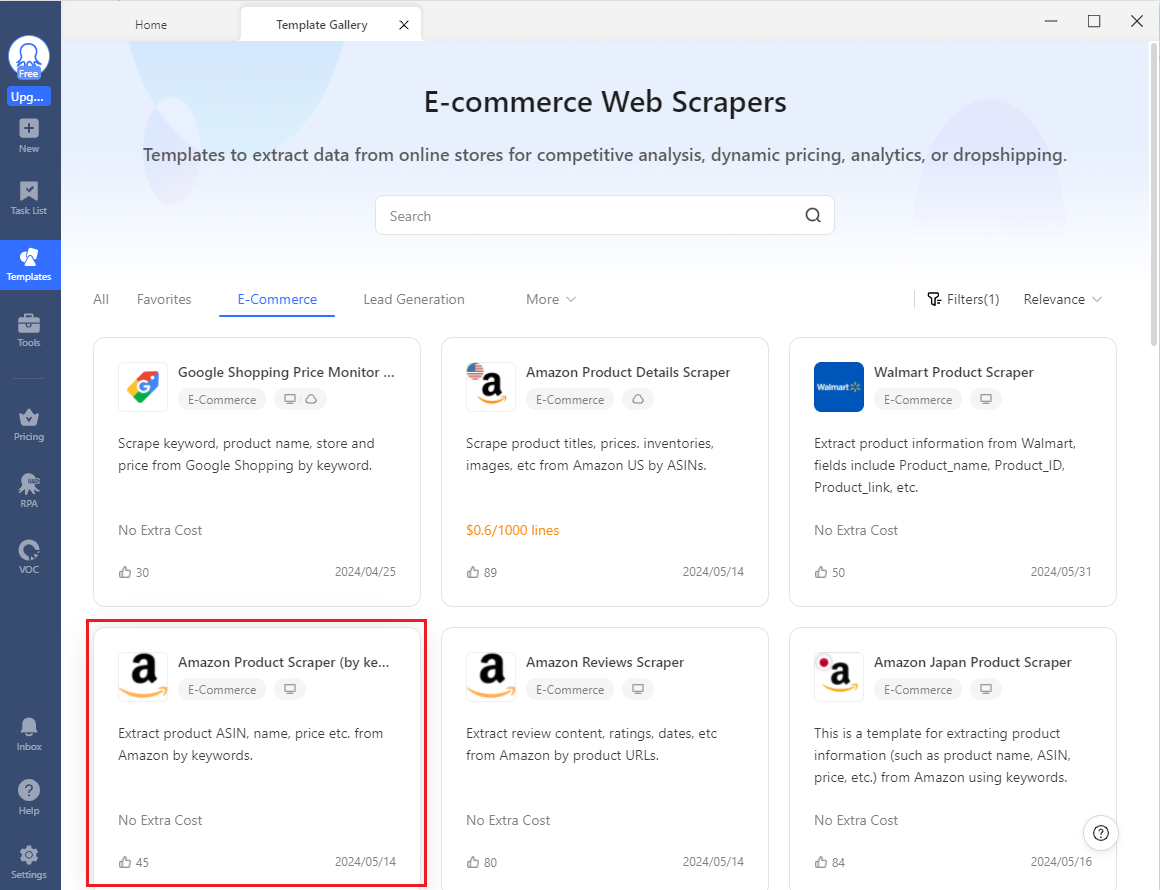
- Choose an appropriate template from the list of templates. For this example, we'll select the Amazon Product Scraper (highlighted in red).
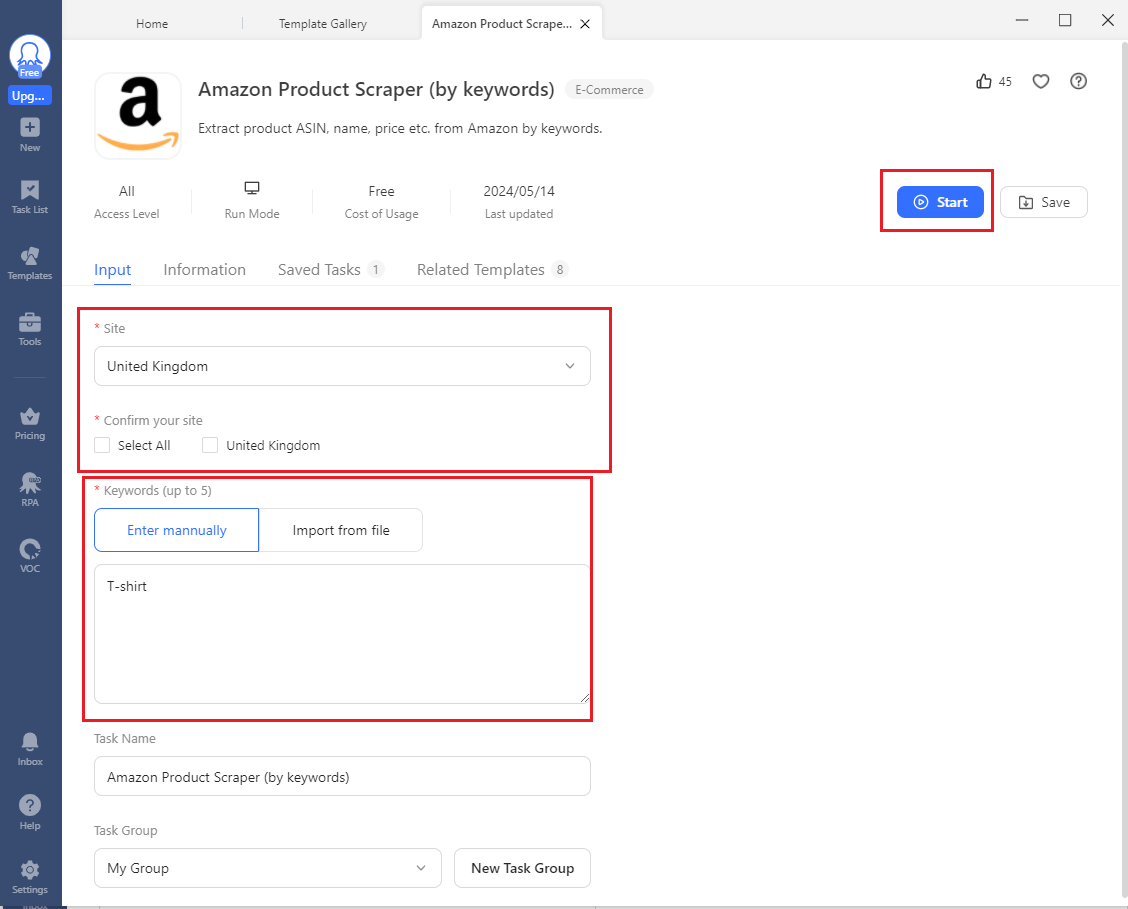
- Next, enter the country you want to target and then enter the keyword you're looking for. For this guide, you'll be using Amazon UK. Ensure you check the boxes for "Select All" and "United Kingdom". Then, choose the "Enter manually" option and enter "T-shirt" for keyword. Finally, hit "Start".
- Next, you'll need to select where you want to run your scraping task. For large-scale extraction jobs, you should probably consider investing in Octoparse's cloud extraction --- which runs your tasks on their highly available cloud servers, in parallel --- but for our needs, doing this locally should be fine. Click on "Standard Mode".
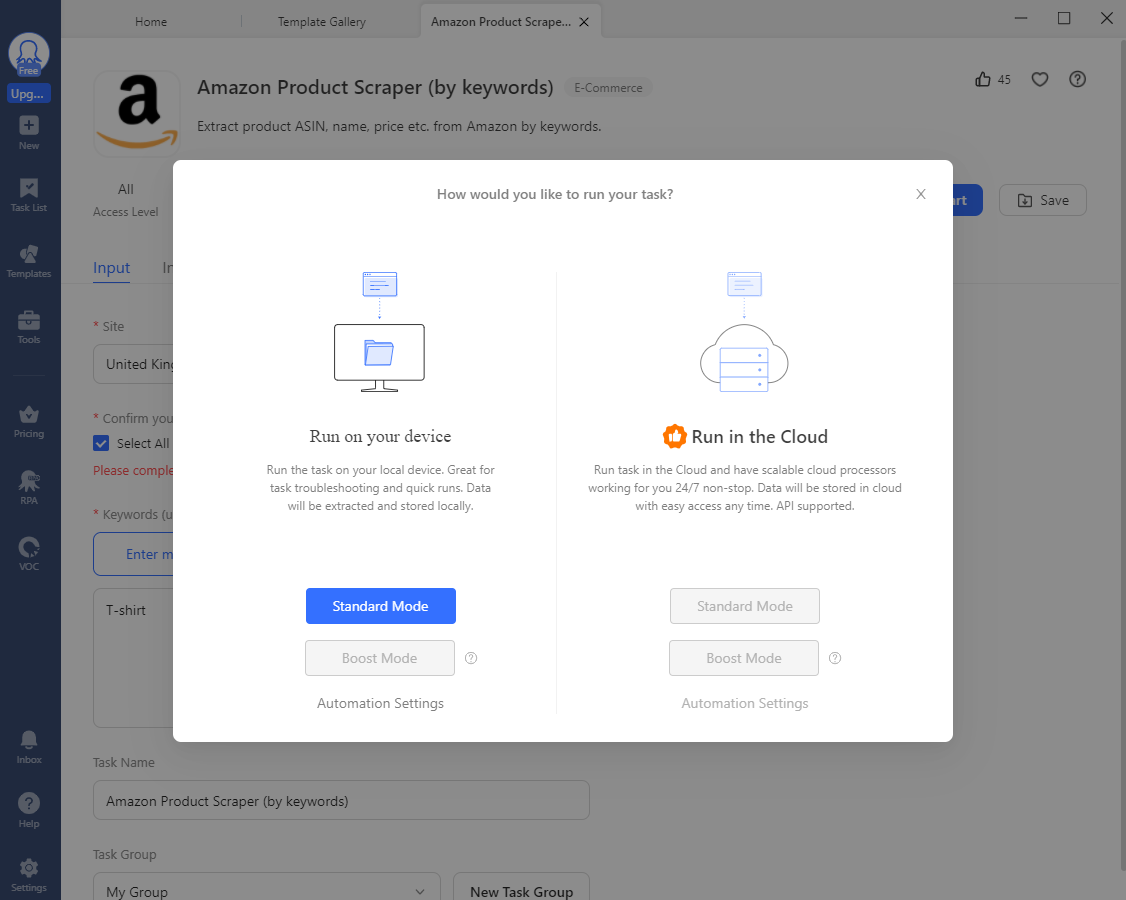
- After this, you'll see your task running in the built-in browser window:
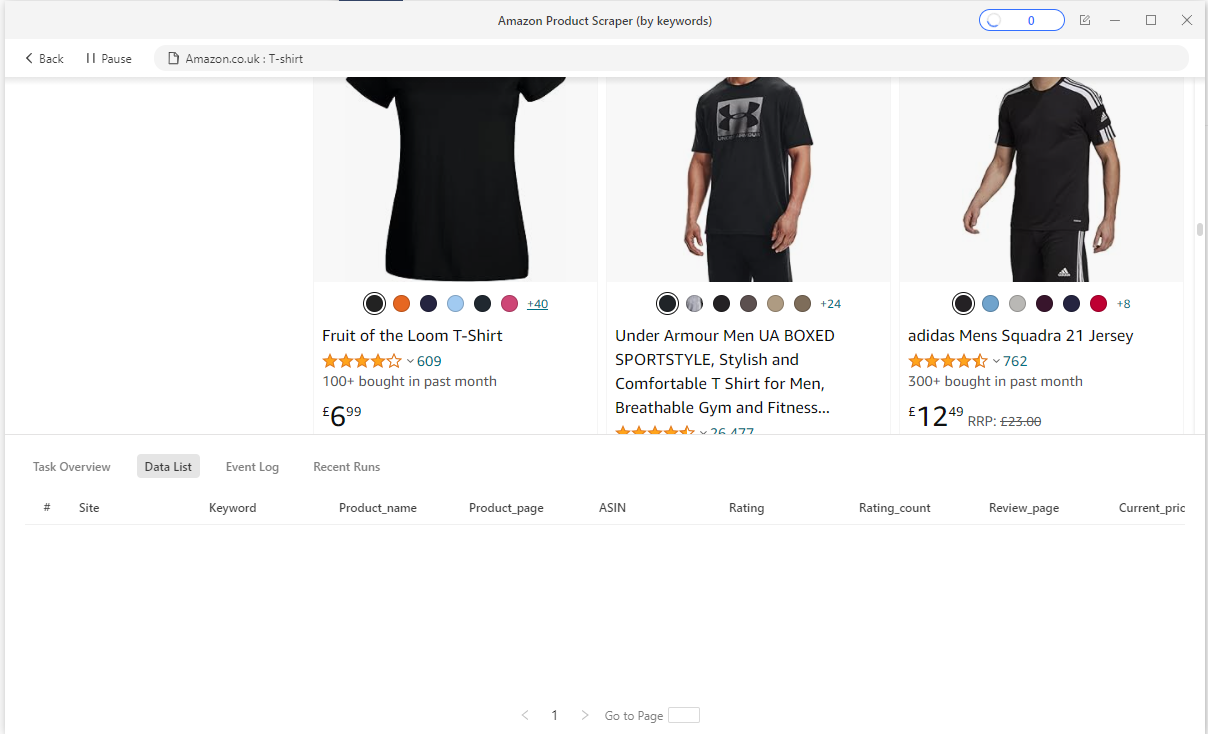
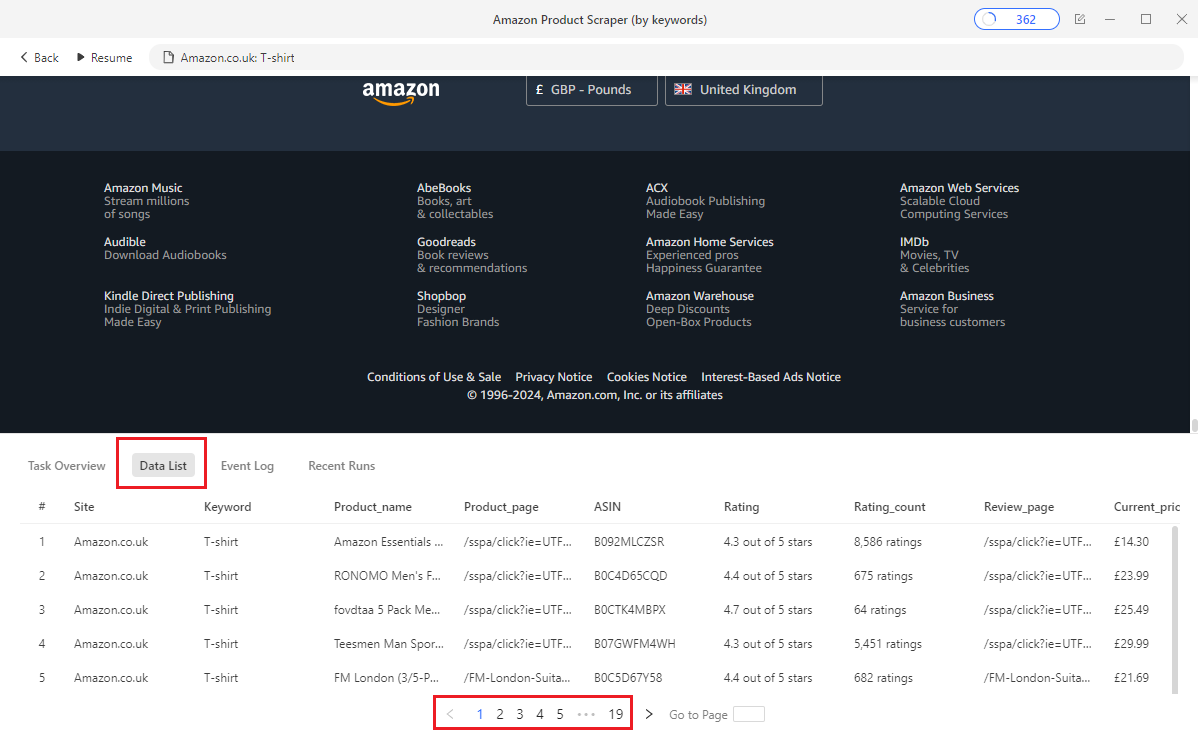
- As the scraper runs, you should see a table (as shown in the screenshot below) consisting of all the data you're scraping from Amazon:
- And now, finally, you can export the data you scraped to your format of choice (Excel, CSV, or JSON) and even save a backup on Octoparse's cloud storage if you so wish.
As you can see, this workflow is entirely automatic, you just need to choose the site and enter a keyword, and the scraper will do the rest. You didn't have to manage proxies or manage request rates, Octoparse took care of all that under the hood. All you had to do was click a few buttons to obtain the data you needed.
Besides the template you saw, there are many other templates for Amazon and e-commerce sites in general that you can use.
Now, if these templates don't cover what you need or if the data you obtained isn't what you were looking for, you could manually point Octoparse to the URL you need and set up a custom workflow by yourself.
In the next section, we'll learn how to do just that, and see what additional customizations we could make.
Step-by-step guide to scraping Amazon with a Custom Task in Octoparse
Octoparse's templates are great for quickly extracting the most common types of data you might need, but if your needs go beyond the basics --- scraping data from entirely different pages, regions, or any complex data that isn't covered by the templates --- you'll need to set up a Custom Task.
For example, what if we wanted to avoid scraping sponsored product listings?
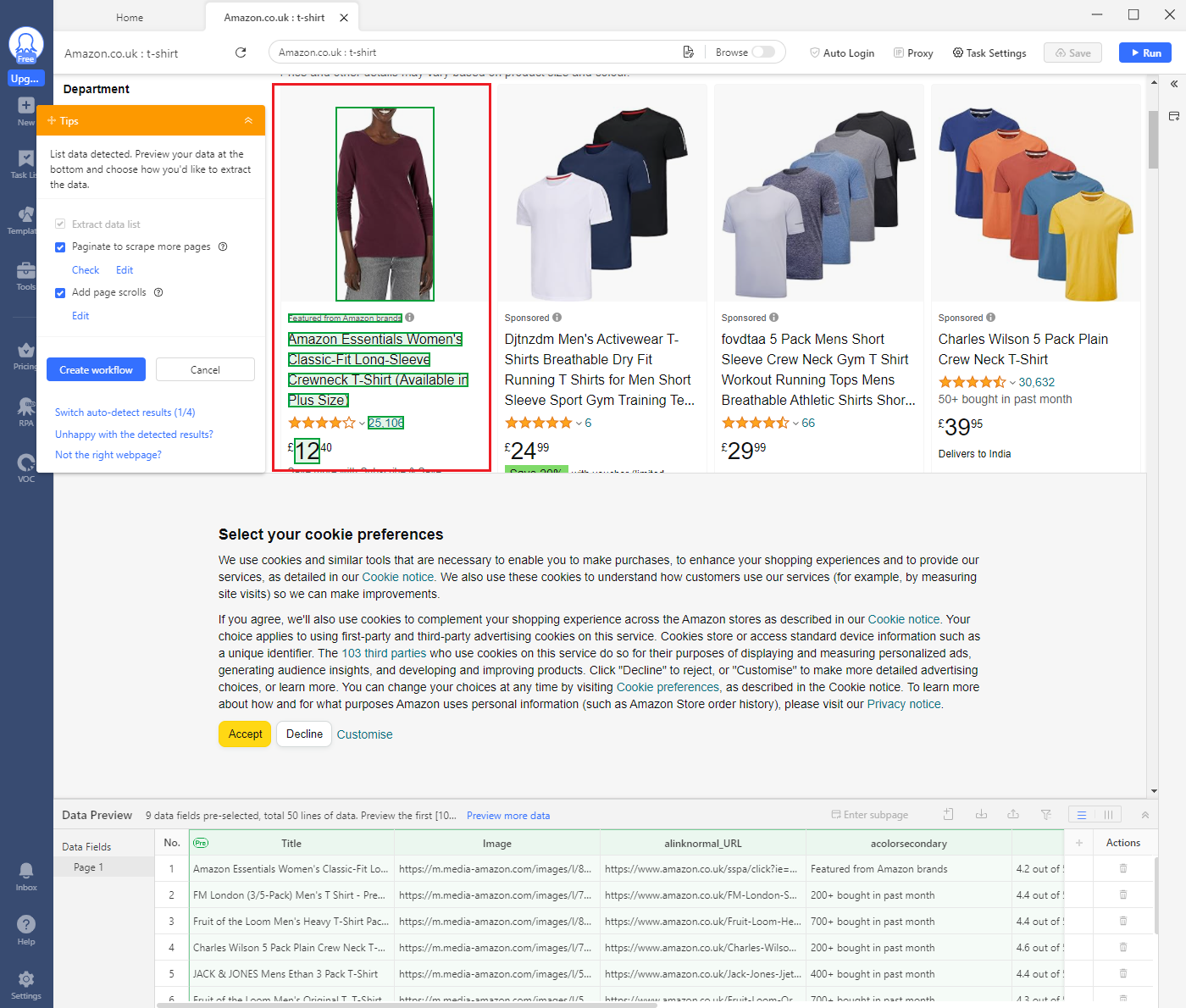
As you can see in the image above, the sponsored items are not highlighted in green, meaning we're skipping over them while scraping.
How? You will see this in the next section when we create the workflow.
You can do a lot of customizations besides the example you just saw, let's cover those in the following lines. We'll mostly stick to the default options, but you'll see all the different types of customizations possible.
Step 1: Configuring a new task
- First, click on 'New Task' and select 'Custom Task' from the dropdown.
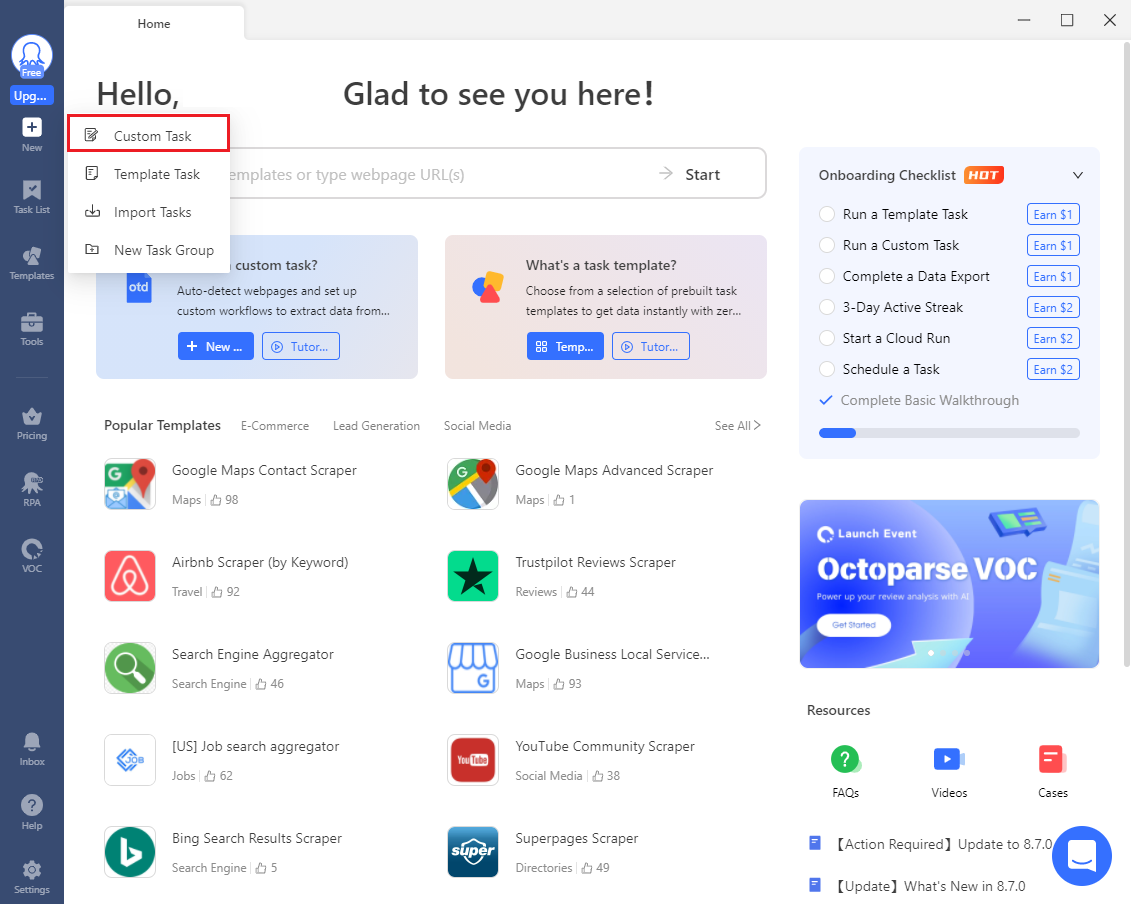
- Next, enter the URL in the 'URL Input' field and hit 'Save'.
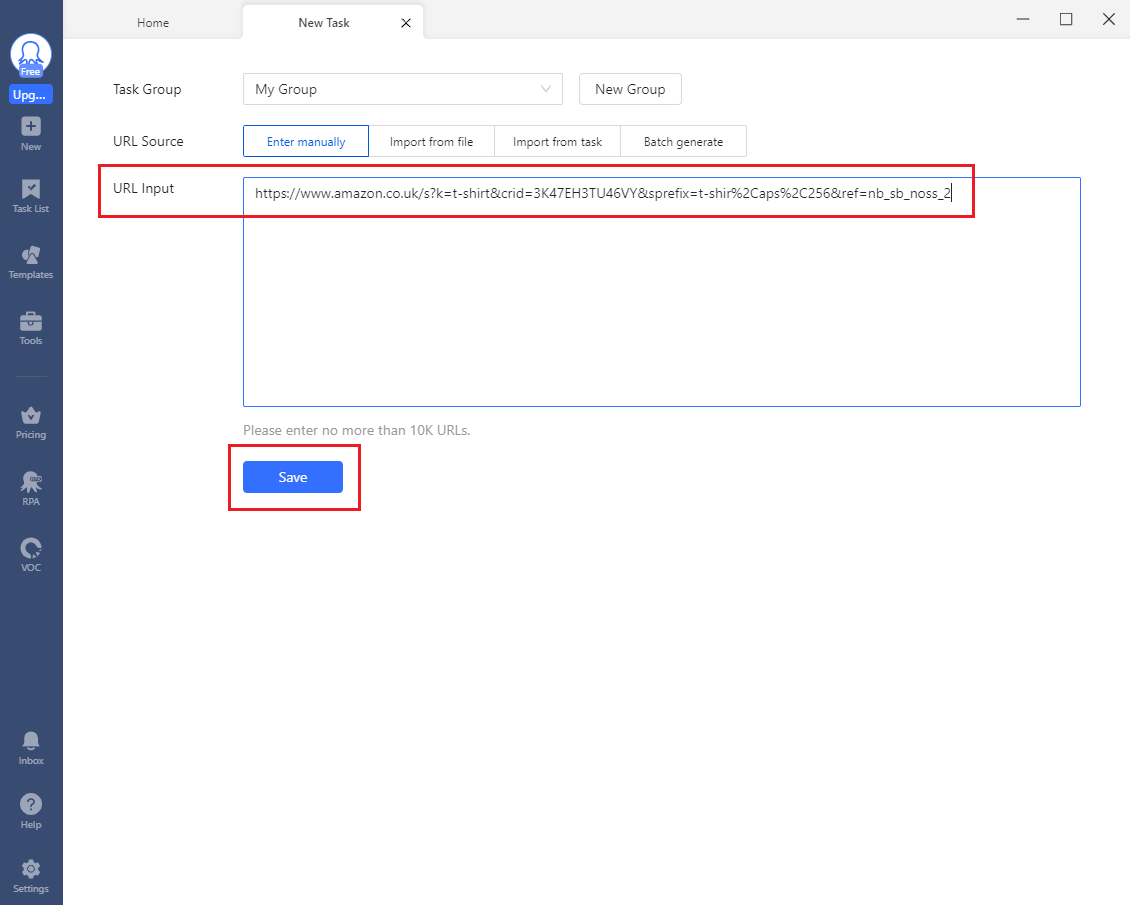
- Following this, wait a bit till the scraper is done detecting all the data.
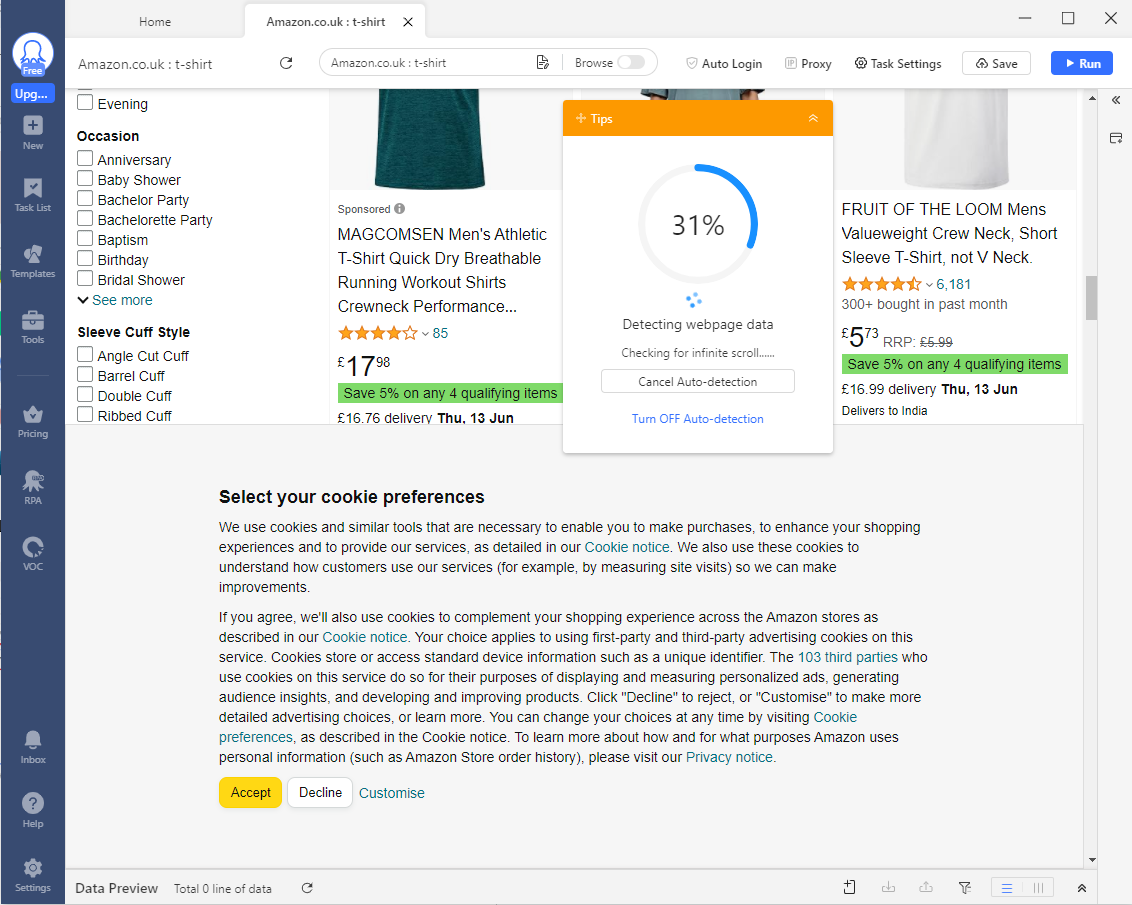
- Once, all the data has been detected, you will find yourself at the following stage:
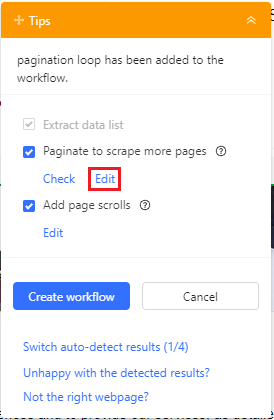
- Here, you need to first 'Edit' the pagination option to point toward the 'Next' button as shown below. This is done so your scraper can browse all the products, page by page. So, after the scraper pulls all the data from the first page, it'll go to the next page and repeat the process.
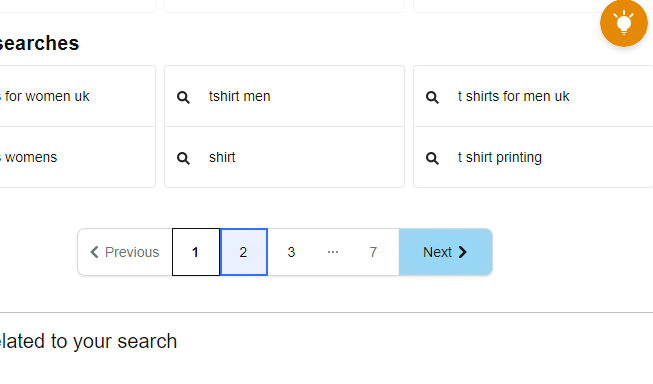
- Also, set the Ajax timeout to 10s. You can set it to as low as 3s if you have a fast internet connection and the pages load up within that. But for this guide, we'll stick to a conservative 10s.
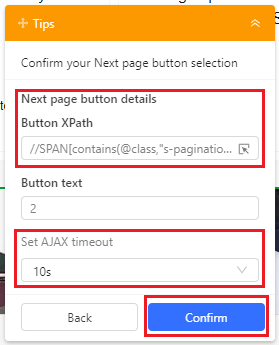
- Finally, we'll go back and click on "Create workflow" to get our task workflow created.
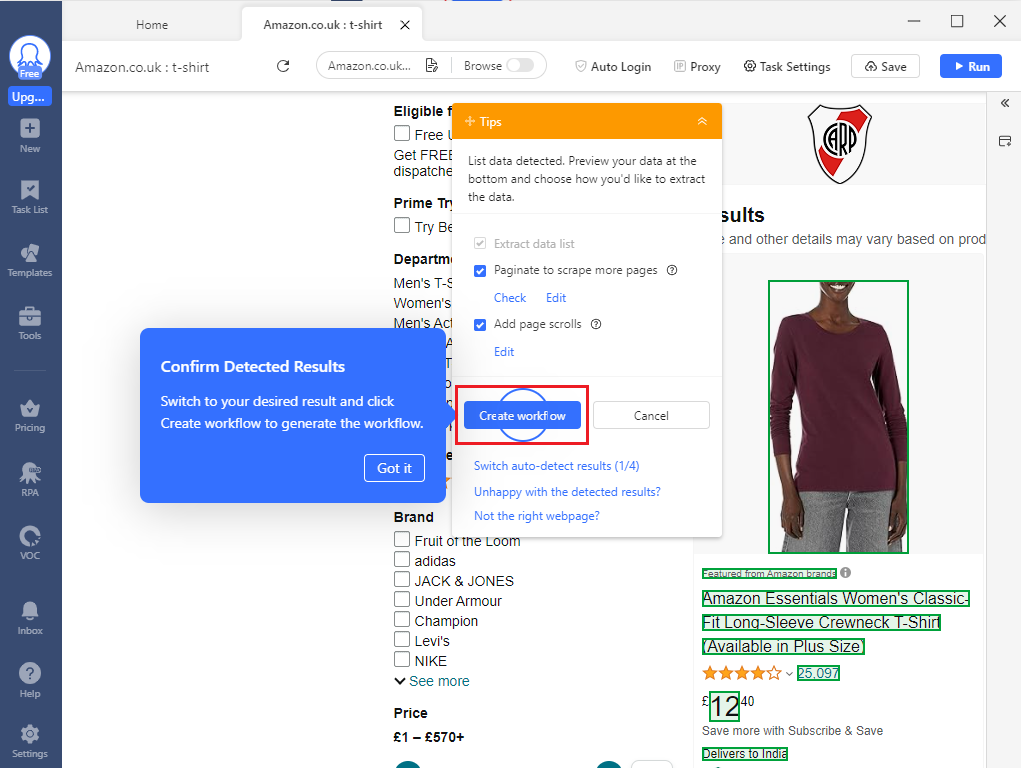
- Here's what your workflow should look like:
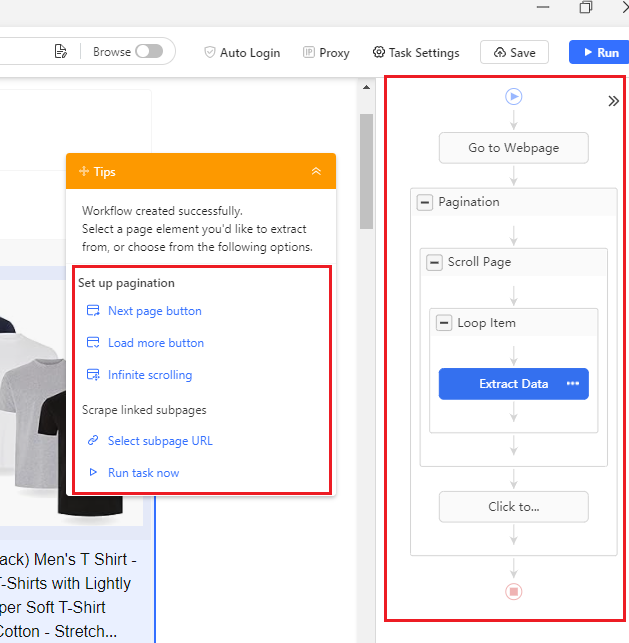
- As you can see from the screenshot, the workflow is highlighted on the right, and on the left, you can see the options for pagination (which we've already set to the 'Next' button) and selecting subpages (ideally, if you want more data from the individual product pages then you can select this option).
You're now done with the workflow and ready to begin the data extraction process. Head over to the next step.
Step 2: Data extraction
- Once you're satisfied, go ahead and hit 'Run' and select 'Standard Mode' just like last time. You can run the scraper in the cloud as well if you've got the cloud option. For this guide, though, running locally will do just fine. Click on 'Standard Mode' to begin.
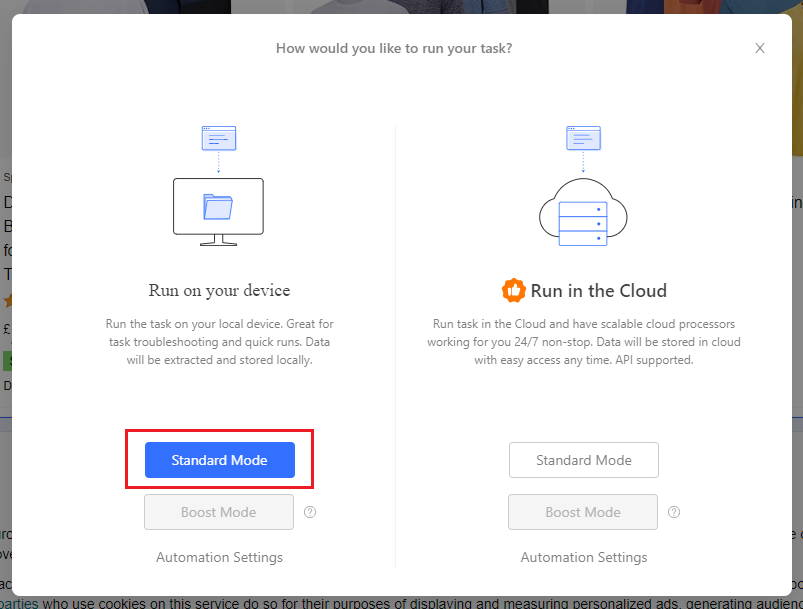
- Once the run completes, you should see the following:
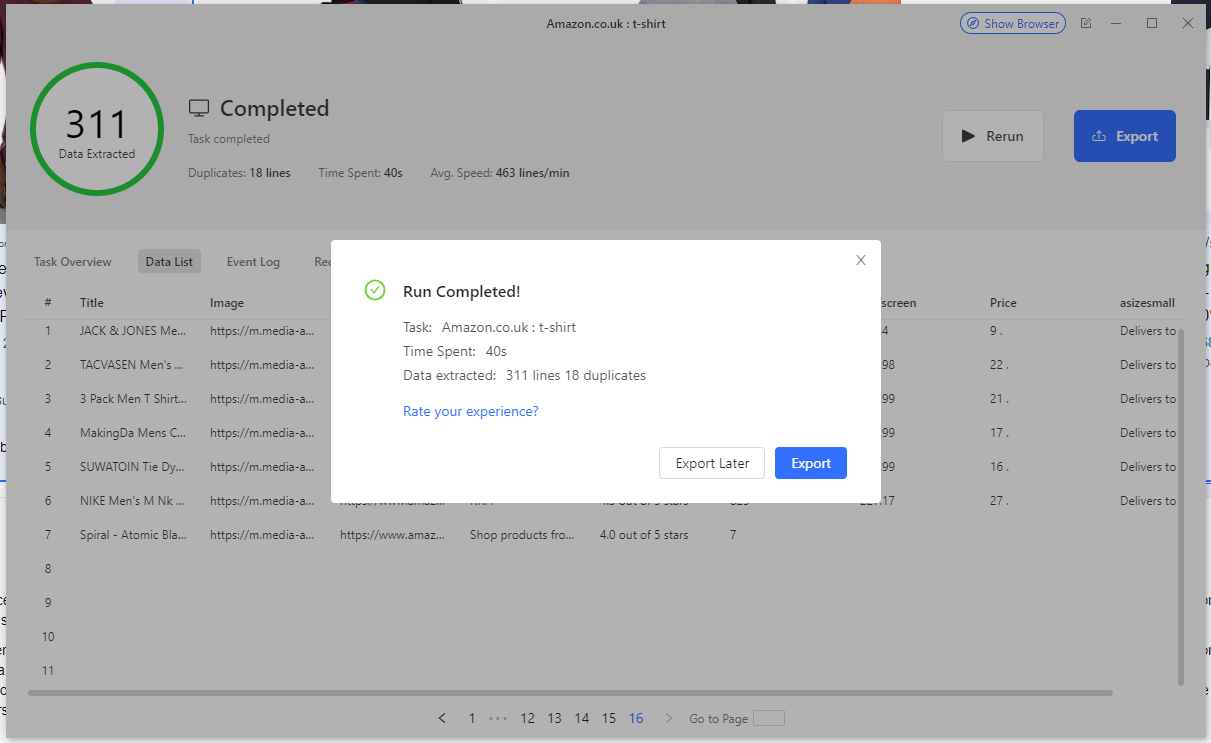
Octoparse is now done extracting all the data you pointed at, all that's left is to export the data.
Step 3: Export
- If you click on 'Export', Octoparse will automatically give you the option to remove duplicates from your table. Very handy!
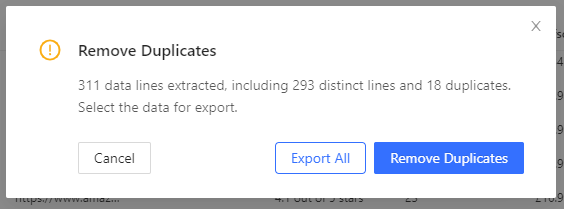
- After removing the duplicates, your data is now ready to be exported. You'll get the following (industry standard) options: Excel, CSV, HTML, JSON, XML, Google Sheets, SqlServer, and MySql. You could also export the data to a local folder of your choice.
For the cloud runs, you could also export the data to Zapier.
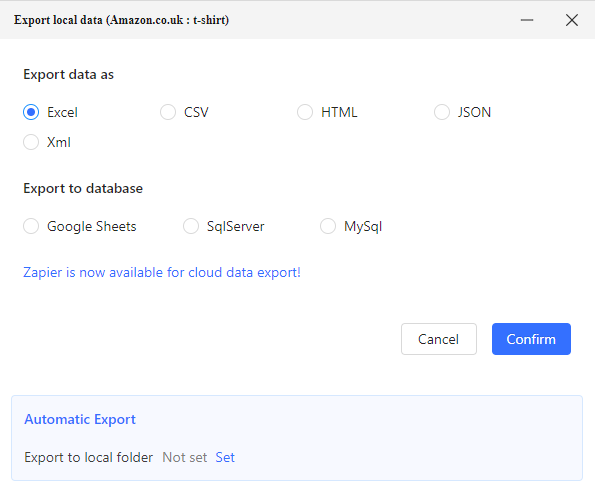
- For this guide, we'll choose Excel and after providing a path, you'll get the Excel file straight to your hard drive.
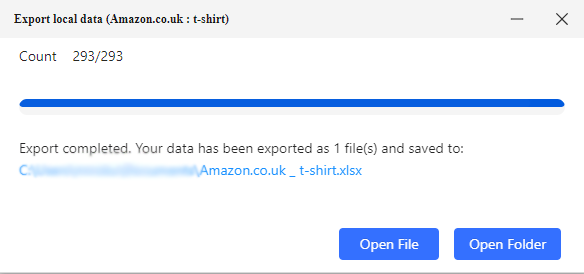
- And this is what your final dataset would look like:
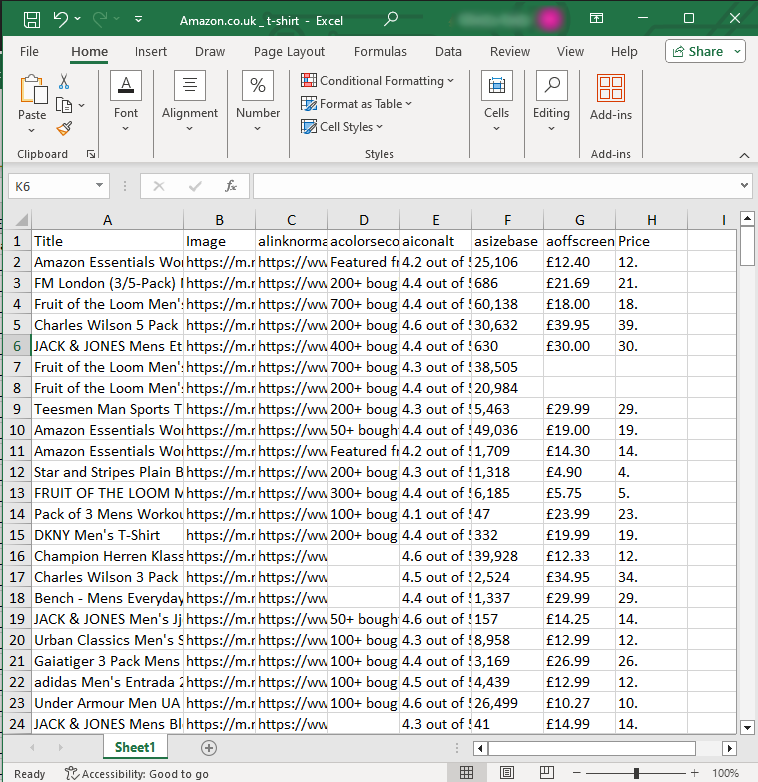
The next two steps are optional but if you're undertaking a big scraping project, then you'd definitely need them.
👉 Please note that if you get stuck anywhere, you can check out Octoparse's blogs and video tutorials. You can also check out their help center here:
Help Center
Help Centerhelpcenter.octoparse.com
(Optional) Step 4: Advanced Options for Custom Tasks
You'll get several customization options if you go into 'Task Settings'.
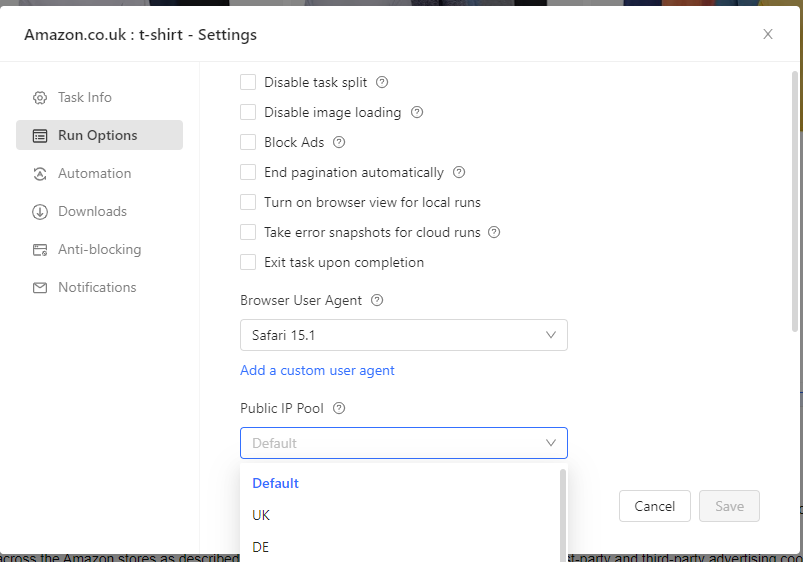
For instance, you can choose your browser user agent and your public IP pool if you wish to use any. If you choose to disable image loading, you can do that as well.
You could automate your scraping tasks if you want by scheduling it to run at specific intervals and then automatically export the gathered data to a database or a local folder, this is great if you want real-time pricing data.
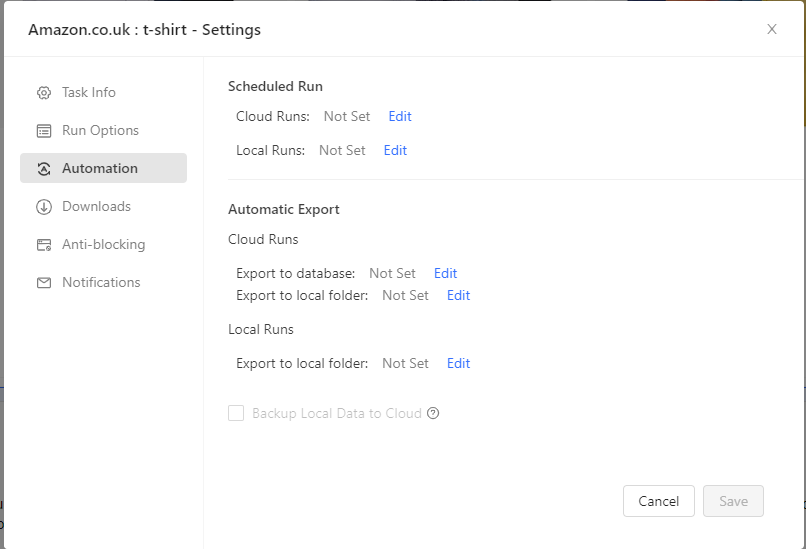
You could set it up to auto-download your data to your local drive upon completion, if you want. If you were using Octoparse's Cloud Extraction, it could also export results directly to your database.
You could also set up proxies. This is great for accessing geo-specific data and bypassing certain blocking mechanisms. Here you could use Octoparse's proxies or configure your own, select Region and rotate them as well. All great features if you're doing large-scale scraping and need to go undetected.
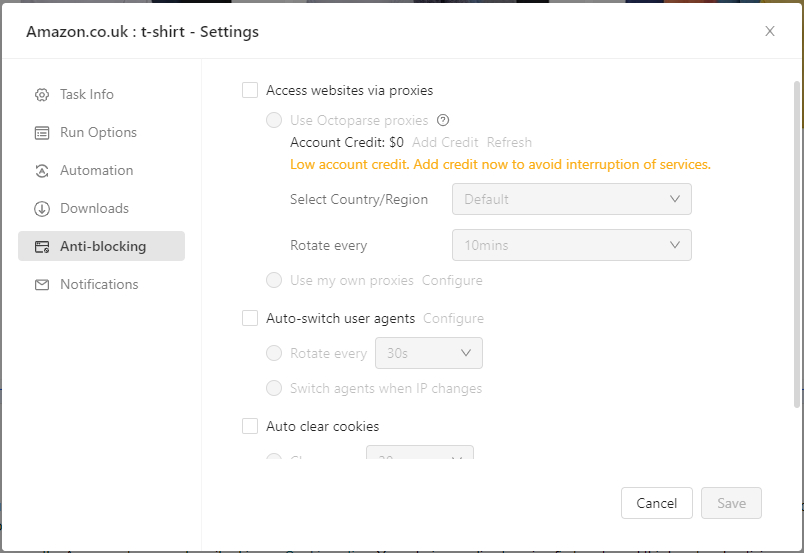
We'll discuss this in a bit more detail later on in this guide.
Finally, you also have the option to set up email notifications once a scraping run is complete.
💡 For a detailed breakdown of all the advanced settings, check out these guides:
Advanced Settings | Help Center
Edit descriptionhelpcenter.octoparse.com
Now, so far, we haven't encountered any anti-scraping mechanisms. But if we did, they could have disrupted your scraping process. In the following step, we'll explore these mechanisms and see how we can bypass them.
(Optional) Step 5: Bypassing Anti-Scraping Measures
A website can implement several anti-scraping mechanisms such as CAPTCHAs, IP-based blocks, and user agent-based blocks. With Octoparse, you can take care of all of these anti-scraping techniques and seamlessly extract the data you need.
For our present setup, we didn't encounter any blocks, but should you come across any, the following section will show you how Octoparse can help you overcome them.
CAPTCHA
It's quite common for a website to implement some sort of CAPTCHA strategy to block automated data extraction. With Octoparse, you can take care of these anti-scraping techniques and seamlessly extract the data you need.
Here's how:
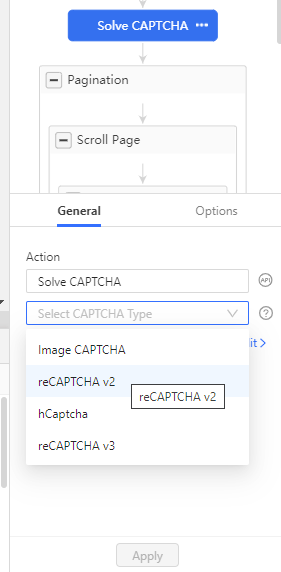
- After you've set your workflow, should you require it, you could add a step for solving CAPTCHAs. You can do so by simply clicking on the '+' button and selecting 'Solve CAPTCHA' from the dropdown as shown below:
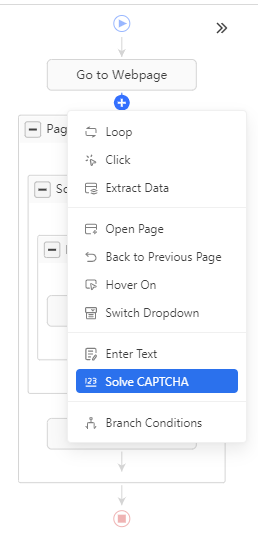
- Next, select the type of CAPTCHA and hit 'Apply'. As of now, Octoparse can automatically solve reCAPTCHA v2, hCaptcha, and reCAPTCHA v3 (at a rate of $1 per 1K solve attempts), while the far rarer Image CAPTCHAs do require manual intervention.
*💡***For more details, check out this guide:**
Resolve Captcha | Help Center
*You are browsing a tutorial guide for the latest Octoparse version. If you are running an older version of Octoparse...*helpcenter.octoparse.com
IP Blocking
Websites monitor IP behavior to spot bots, often blocking IPs with excessive requests.
- To avoid getting blocked you canslow down the scraping speed, use random delays, and rotate IP addresses. Octoparse gives you two options when it comes to using proxies, you can either choose Octoparse's proxies, select a country/region of your choice, and set the rotation at an interval of your choice.
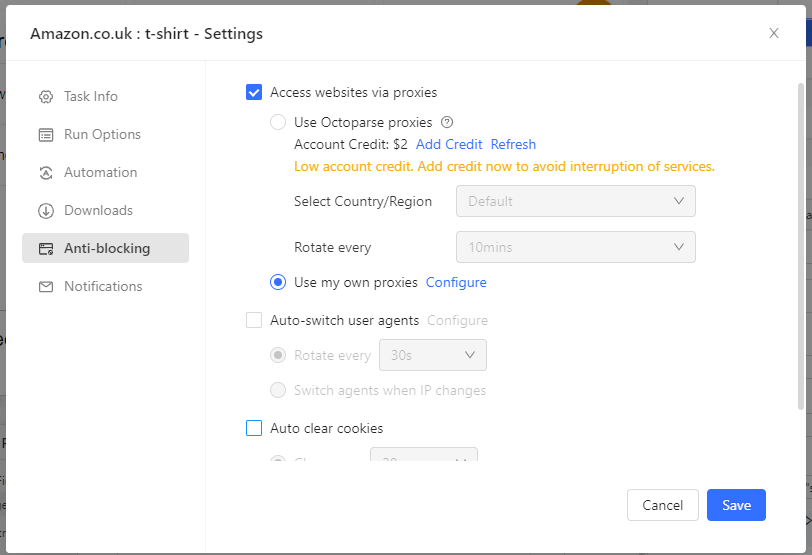
- Or, you can also use your own proxies. Select 'Use my own proxies' and click the Configure button to type in your list of proxy servers and set the rotation interval:
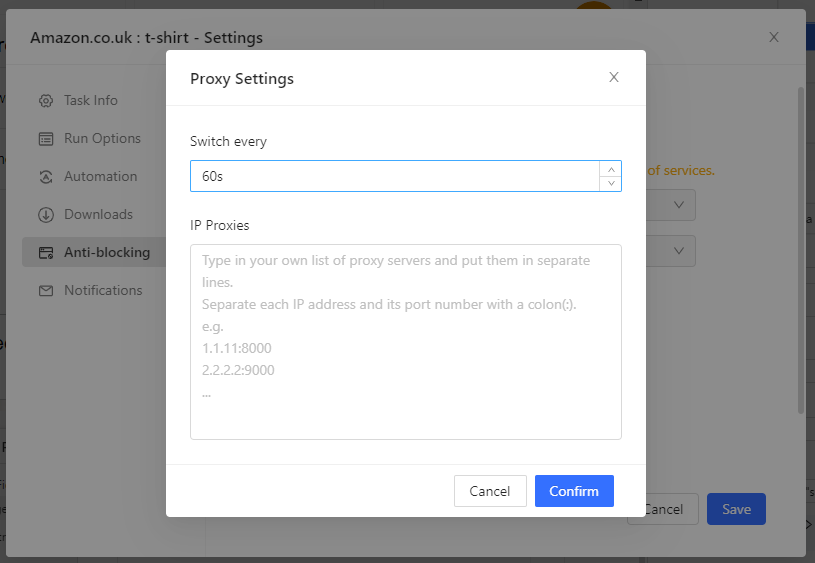
- After you're done configuring your proxies, you should hit confirm and save your settings.
💡 For more details, check out this guide:
Set up IP Proxies | Help Center
*You are browsing a tutorial guide for the latest Octoparse version. If you are running an older version of Octoparse...*helpcenter.octoparse.com
User Agent
Websites check the UA string to identify non-browser traffic, blocking requests without proper headers.
- To bypass this, you can select a range of user agents Oxylabs provides, and rotate them at certain intervals or with each IP rotation.
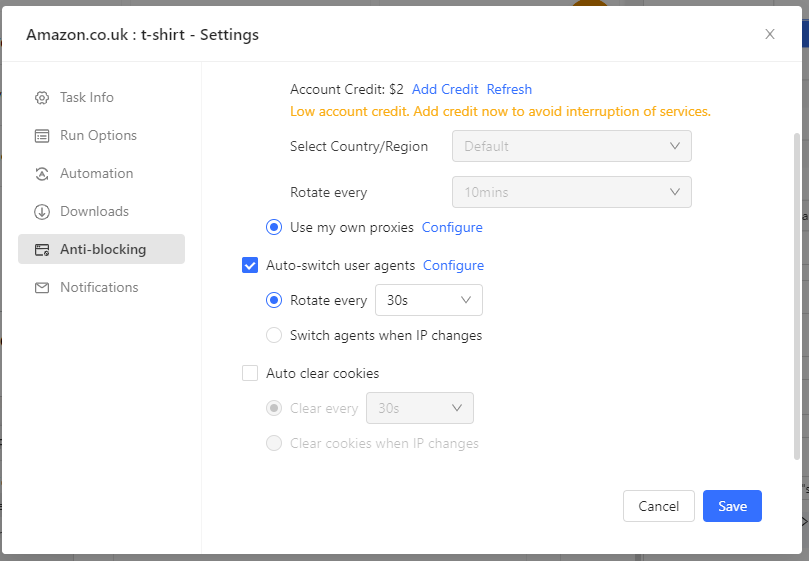
- If you click on Configure, you'll see this modal with all the UA options you're getting.
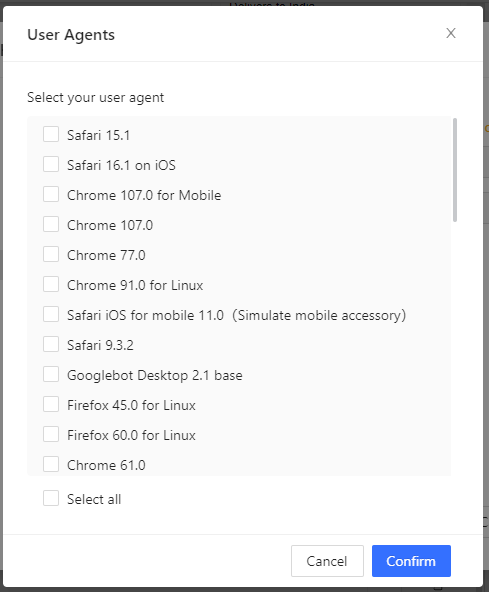
- Choose the appropriate options or select all of them, hit confirm, and then save your settings.
💡 Check out this guide for more information regarding further customization:
Add custom User Agent | Help Center
*Sometimes you will encounter the problem that some websites cannot be opened in the Octoparse but work well in the...*helpcenter.octoparse.com
Now you no longer have to worry about your scraper getting stuck mid-process. You can seamlessly extract data from Amazon, store it in a format of your choice, perform analysis, and derive priceless insights.
Do More With Your Extracted Data: Octoparse RPA + Octoparse VOC
Extracting data is just the beginning. Octoparse offers even more no-code tooling, equally as robust, enabling you to automate your entire data pipeline and derive actionable insights from your extracted data.
Octoparse workflow automation allows you to customize and automate data extraction and processing, saving you time and effort, and streamlining the transformation of raw data into strategic decisions.
Meanwhile, Octoparse VOC leverages AI to analyze that extracted data, including customer review analysis and sentiment analysis, providing deeper understanding and valuable insights. By leveraging natural language processing (NLP) to identify how customers really feel, the common issues and problems they frequently mention, and the key factors that influence their satisfaction, you can turn raw customer feedback into actionable intelligence --- no need for tediously cleaning and structuring your data, and then consulting professionals for the reports you need.
Benefits of Octoparse's No-Code Data Scraper
- Easy to use: Octoparse has a user-friendly interface, it's accessible and has plenty of guides and tutorials, making onboarding easier. As you saw in the guide, you simply point and click to select the data you want and the scraper will do the rest. You can basically get started in seconds if you're using Octoparse's templates. You can also do a lot of customizations if you opt to build a custom workflow; useful for large-scale scraping tasks.
- Cost-effective: Octoparse offers a cost-effective solution for data collection, saving you significant resources in market research and analysis. You can get the standard plan for as low as $75 per month. For more details, check out Octoparse's pricing page.
- Flexible and scalable: Scales with your needs, scraping large datasets at high speeds. You can also customize workflows for diverse needs and adapt to different platforms, not just e-commerce sites.
- Task Automation with Octoparse RPA: With Octoparse RPA, you can go beyond simple scraping and automate your data extraction, processing, and export as a whole --- dragging-and-dropping a library of actions mimicking human behavior on a webpage to build RPA automations for data extraction, processing, and export. You could even integrate your extracted data with BI tools for deeper insights. Octoparse RPA's pricing plans can be seen here.
- Instantly generate actionable insights with Octoparse VOC: Octoparse VOC is a next-gen AI-powered voice-of-the-customer assistant, that quickly provides actionable insights by aggregating and analyzing your data --- be it sentiment analysis from scraped product reviews, performing real-time analysis on product pages without even extracting any data, identifying hidden concerns by analyzing Customer FAQ sections, and even enabling professional competitor benchmarking with side-by-side comparisons. Check out Octoparse VOC's pricing here.
Octoparse's suite of no-code scraping tools goes beyond web scraping --- it can automate and streamline your entire data pipeline --- from extraction to cleaning, export, and even generating reports and analysis. All the data you need, all with one Octoparse account.
Conclusion
E-commerce marketplaces like Amazon are data-rich platforms, making the collection and analysis of this data crucial for businesses and individuals looking to maintain a competitive edge. Whether through market research, customer sentiment analysis, or other methods, deriving key insights from this data is essential in this highly competitive industry.
Octoparse offers a user-friendly, no-code solution for data scraping from e-commerce sites like Amazon that simplifies data extraction for users of all technical skill levels.
With its visual workflow designer, pre-configured templates, advanced capabilities for handling IP rotation, CAPTCHA solving, and proxies, and advanced tooling like RPA and VOC that can automate your workflow and use the power of LLMs to generate human-quality reports and insights for you --- you can effortlessly extract and transform raw data into actionable intelligence, driving smarter decisions and enhancing your competitive edge.
Whether you're a marketer, a small business owner, or someone simply curious about data extraction, Octoparse provides a powerful yet accessible way to gather and analyze e-commerce data.
Sign up for a free trial today and see how easily you can start extracting valuable data to drive informed decision-making and gain a competitive edge in the e-commerce landscape.
Comments
Loading comments…