
Last time, we talked about Pydantic as a library to parse json-like data coming from API sources at run time. Today, we want to briefly introduce how you could validate your dataframes with Pytest. Based on the official documentation, Pytest is a Python testing library, which “makes it easy to write small tests, yet scales to support complex functional testing for applications and libraries”. This validation step is important as typically you would want to make sure the data is correctly transformed before storing it into the database and that typically happens on the level of dataframes for structured data tables rather than json structures directly from APIs.
When You Should Validate Data:
Based on what we have learned in the past, we have also summarized the following good practices for validating data. Please take it with a grain of salt, as different companies might have different scenarios and data needs.
-
Data validation should be done as early as possible and to be done as often as possible.
-
Data validation should be done by all data developers, including developers who prepare data (Data Engineer) and developers who use data (Data Analyst or Data Scientist).
-
Data validation should be done for both data input and data output.
Note: This post is more so focused on the post-transformed output dataframe prior to data storage versus data input prior to data transformation (see the last post with Pydantic for this). We are not showing the “transformation” steps as they can be the custom transformation code from developers and they are not the focus of this post.
Testing Data Source:
We are using the same data source, Ipstack, for continuation from our last post, which focuses on ingested data from an API before data transformation. From Ipstack, which is an API that provides geolocation and identification data for IP addresses
We are using a real-life data source. Ipstack provides a free plan for everyone who signs up, so if you would like to follow along with the example, feel free to register a free account with them. Disclaimer: we are not commercially affiliated with Ipstack.
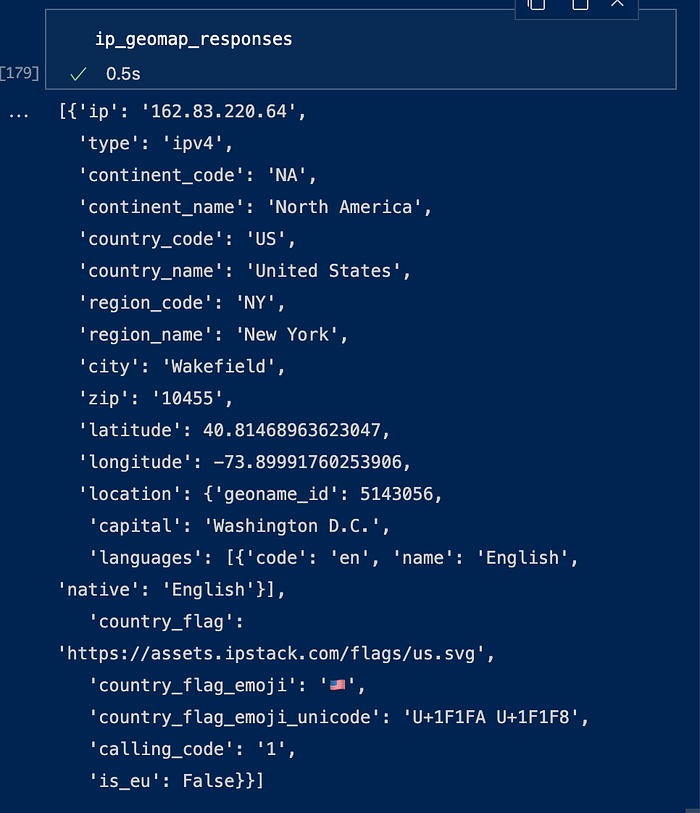
Sample Response from API:
What to Validate:
-
Validate the dataframe to check if there are any duplicated rows. If yes, fail the test. If not, then the test succeeds.
-
Validate data types of each column of the dataframe. If datatypes don't match, fail the test. If they all match, then the test succeeds.
-
Validate if the dataframe contains all the columns needed. If not, fail the test. If yes, then the test succeeds.
How to Set It Up:
$ pip install pytest
In the test file, you would want to import the module with the following import statement. Note that your test file name has to start with “test”, to be recognized by Pytest.
#test_pytest_example.py file name has to follow test*
import pytest
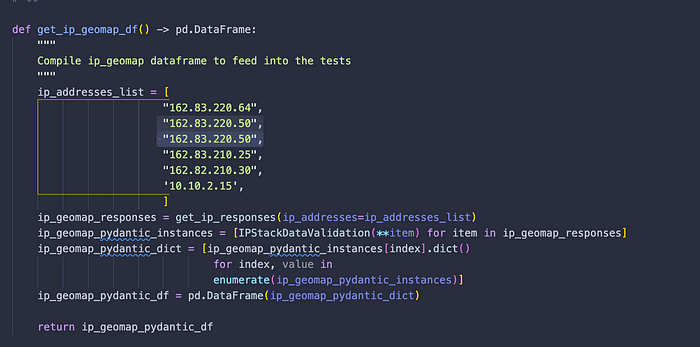
We also want to create our prerequisite step function to get dataframes to feed into our tests. Note that we are getting our data directly from the Pydantic classes, which helped us to parse and validate the data from the API. Check the previous post if you want to see how these Pydantic classes are defined.

The Components of a Test:
Typically a test would include the following components:
- Prerequisite steps: the prerequisite steps to collect data to feed into the pytest fixtures. This is where you can write your custom steps to collect data.
- Pytest Fixture: the arrangement step for your test function to call. A Pytest fixture is represented by the decorator @pytest.fixture.
- A Test Function: the actual function that incorporates the Pytest fixture and an assert statement to execute the test.
How to Create the Tests:
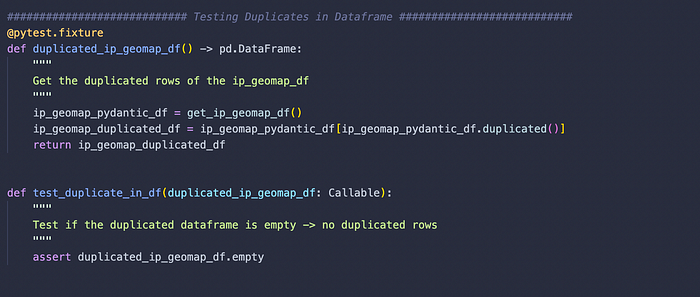
#1. Validate if there are any duplicated rows. If yes, fail the test. If not, then the test succeeds.
To evaluate if there are duplicated rows, we can get a dataframe that would contain duplicated rows. And then we can evaluate if the dataframe is empty. Therefore, we write the pytest.fixture to get the duplicated dataframe. And then we pass that into the actual test function to evaluate if it's empty with an assert statement.
Note: Just like the file name, the actual test functions need to be named with “test” at the beginning.
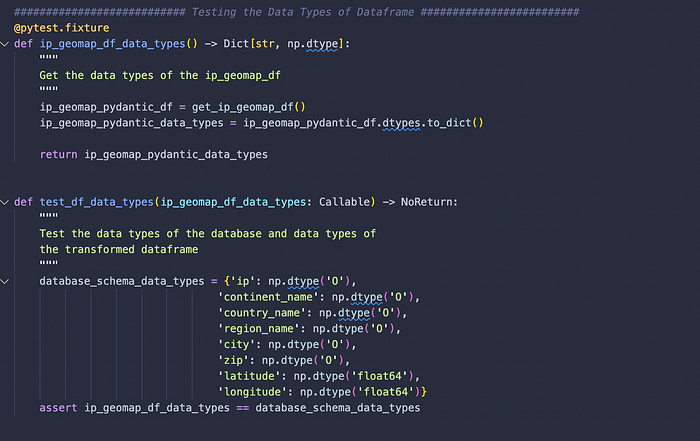
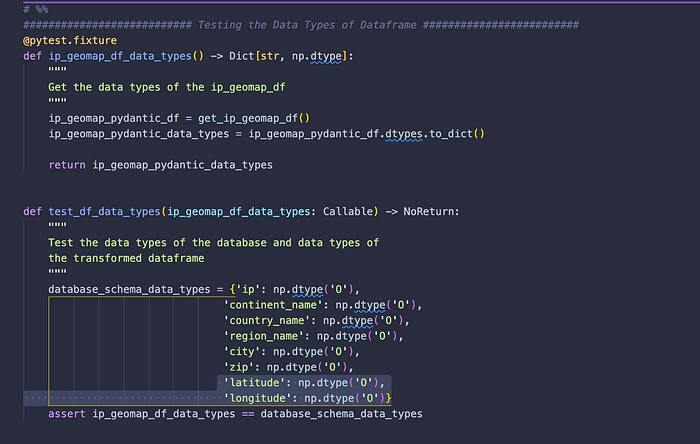
#2. Validate data types of each column of the dataframe. If data types don't match, fail the test. If they all match, then the test succeeds.
To validate the data types of each column of a dataframe, we can use pd.DataFrame.dtypes attribute and convert that into a dictionary. And then we can evaluate if that dictionary matches the data types from a potential database that we have set up.
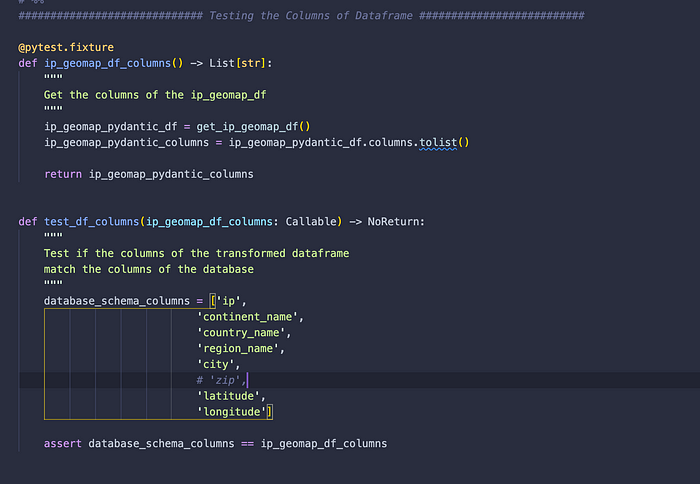
3. Validate if the dataframe contains all the columns needed. If not, fail the test. If yes, then the test succeeds.
To validate if a dataframe contains all the columns that we need to properly push this dataframe into the database, we can just evaluate if the pd.DataFrame.columns.tolist() matches the list of columns that we are currently using for the database. Again, the actual test is executed with the assert statement.

Running the Tests:
You can run the test by running the following command. Note that the file name has to start with “test” to be recognized by pytest.
$pytest test_pytest_example.py
As you can see, all my tests ran through successfully!

But how do I know if my tests are catching the invalid dataframes?
Confirming the Tests:
Let's tweak the tests to confirm that they can validate incorrect dataframes.
Let's add in a duplicated IP address, “162.83.220.50” to confirm if the first test is working.
Let's change the schema of the database to be objects or strings to confirm if the second test is working:
Let's eliminate a field within the database_schema_columns list to confirm if the third test is working:
And then let's run the tests again:
Great. The first test failed with an assertion error. As we know, we inputted a duplicated IP address. Therefore the duplicated dataframe is no longer empty, hence failing the test.
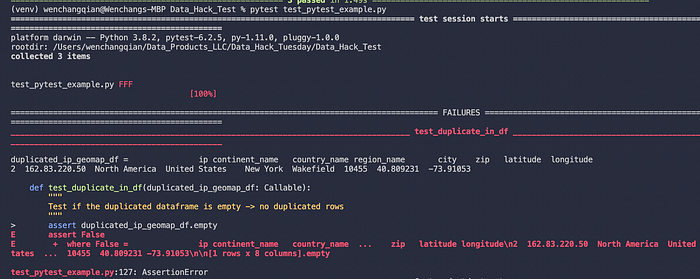
The second test also failed as expected, as now the database_schema_data_types dictionary no longer matches with the output data frame's data types.

Finally, the third test failed as expected as well, as now the columns of the output dataframe no longer match the database_schema_column list.
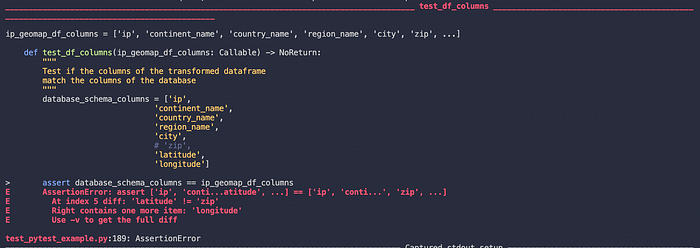
Awesome, this should assure us that our tests are working with the output dataframe and we can feel relatively comfortable pushing this dataframe to our database.
Hope you find this helpful!
Comments
Loading comments…