
Introduction
Imagine a world where the capability to interact and explore the wide universe of NLP is just an API call away! Today, we dive into the implementation of a Flask API to load the mighty LLaMA models. Our journey involves the incredible LLaMA Flask implementation, provided with the benevolence of an Apache 2.0 license, granting developers the power to embark on adventurous NLP endeavours.
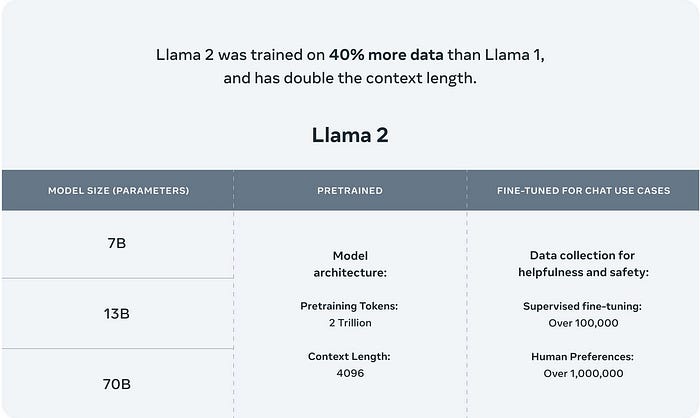
Meta’s open-sourced Large Language Model (LLM), Llama 2, has unfolded new horizons in the realm of AI, offering developers and businesses a wealth of opportunities. With its impressive 70B parameters and the Llama 2 family models, this initiative has sent waves through the AI community. Notably, Llama 2 holds a commendable third-place position in the Open LLM leaderboard, showcasing its potential in diverse applications.
The Significance of Llama 2 in the AI Space
Llama 2 does not only serve as a powerful tool but also embodies Meta’s inclusive approach towards technology, propelling open-source AI development by making such a significant model accessible to the public. The inclusive license, allowing even commercial use, paves the way for innovation across sectors, providing a robust alternative to the likes of GPT-3.5 and GPT-4.
Deciphering Lit-LLaMA
Before delving into API development, let’s familiarize ourselves with Lit-LLaMA, a variant of the LLaMA model. Lit-LLaMA stands out with its open-source nature under the Apache 2.0 license, in contrast to the original LLaMA’s GPL license. It comes with a design that’s simple, correct, optimized, and without any strings attached. For a detailed understanding, be sure to explore their documentation and setup instructions.
Engaging with Llama 2: Understanding Prompt Engineering
Working with Llama 2 entails a nuanced understanding of prompt engineering, wherein specific templates guide the model to generate relevant responses. The unique prompt format of Llama 2 initiates a conversation as follows:
<s>[INST] <<SYS>> {{ system_prompt }} <</SYS>> {{ user_message }} [/INST]
Where system_prompt sets the context for model responses and user_message seeks specific answers. This interactive method ensures that the model generates relevant, context-aware responses, aligning the interaction closer to human-like conversation. For iterative conversations, every new user message and model response is appended to preserve context, offering a smooth, coherent dialogue experience.
API Design with Flask
The heart of our expedition lies in developing a Flask API, which will serve as a bridge, connecting developers and LLaMA’s capabilities.
Technical Dive: Building a Flask API for Llama 2
In crafting an API using Flask to tap into Llama 2’s capabilities, we need to delve into each section of the code meticulously, ensuring our API is not only functional but also optimized for performance and scalability. Let’s proceed to disentangle the API code to comprehend each segment thoroughly:
Choosing a GPU
For different model sizes of LLaMA you will need different GPU specifications:
- LLaMA 7B and 13B: Nvidia A500 with 24GB should suffice.
- LLaMA 30B: You should opt for at least an Nvidia A40 with 48GB.
API Setup
First, make sure to install the required dependencies:
Setting Up Virtual Environment
- Install Virtual Environment:
Ensure that Python 3 and pip are installed and then run:
pip install virtualenv
- Create Virtual Environment:
Navigate to the project directory and run:
virtualenv venv
- Activate Virtual Environment:
Windows:
.\venv\Scripts\activate
Linux/Mac:
source venv/bin/activate
4. Setup
Clone the repo
git clone https://github.com/Lightning-AI/lit-llama
cd lit-llama
Install dependencies
pip install -r requirements.txt
You are all set! 🎉
Once your environment is set, we commence by developing our API endpoints using Flask.
Building Blocks of the Flask API
Here’s a simplified version of what the API might look like using Flask, with each module/function/class explained.
1. Initialization and Configuration
Before diving into the classes and functions, initialize and configure the Flask application.
from flask import Flask, request, jsonify
app = Flask(__name__)
In this snippet, the Flask application is initialized and the necessary modules are imported. request is used to handle HTTP requests, and jsonify is used to convert Python objects to JSON format.
2. The Llama Model Loader Class
To manage interactions with the Llama model, let’s create a class that will handle the model loading and text generation.
class LlamaModel:
def __init__(self, model_name: str):
self.model = self._load_model(model_name)
def _load_model(self, model_name):
# Logic for loading the Llama model
pass
def generate_text(self, prompt: str) -> str:
# Logic for generating text using the Llama model
pass
__init__initializes a new instance of the class and triggers the model loading._load_modelcontains logic to load the Llama model (could use Hugging Face transformers library, for example).generate_textuses the loaded model to produce text based on the provided prompt.
3. Route to Generate Text
Let’s define a route where clients can send a POST request to get generated text from Llama.
@app.route('/generate', methods=['POST'])
def generate():
data = request.get_json()
prompt = data.get('prompt')
# Validate the prompt
if not prompt:
return jsonify({'error': 'Prompt is missing'}), 400
# Use Llama model to generate text
model = LlamaModel('Llama2')
generated_text = model.generate_text(prompt)
return jsonify({'generated_text': generated_text})
In the /generate route:
datafetches the incoming JSON payload from the POST request.- The prompt is extracted and validated to ensure it’s present.
- A new instance of
LlamaModelis created, specifying the model to be used ('Llama2'in this example). generate_textis called with the prompt and the response is sent back as JSON.
4. Error Handling
Proper error handling is crucial to ensure that the API provides useful feedback and doesn’t crash unexpectedly.
@app.errorhandler(500)
def handle_500(error):
return jsonify({'error': 'Internal server error'}), 500
The handle_500 function returns a JSON object informing the client of an internal server error and sends an HTTP 500 status code.
5. Running the Application
Finally, the application needs to be run. This is usually done with the following snippet:
if __name__ == "__main__":
app.run(port=5000, debug=True)
6. How to Run API Using Gunicorn
- Install
gunicorn:
pip install gunicorn
- Run
gunicornwith the desired number of worker processes and bind it to the API’s endpoint. Here,your_api:appspecifies the module and the Flask app instance:
gunicorn -w 4 -b 0.0.0.0:5000 your_api:app
Setting Up Gunicorn as a Service
- Create a Gunicorn systemd service file, e.g.,
/etc/systemd/system/your_api.service:
[Unit]
Description=Gunicorn instance to serve your API
After=network.target
[Service]
User=your_user
Group=www-data
WorkingDirectory=/path/to/your_api
Environment="PATH=/path/to/your_api/llama-flask-env/bin"
ExecStart=/path/to/your_api/llama-flask-env/bin/gunicorn --workers 1--bind unix:your_api.sock -m 007 your_api:app
[Install]
WantedBy=multi-user.target
- Start the Gunicorn service and enable it to launch on boot:
sudo systemctl start your_api
sudo systemctl enable your_api
API Usage Example with Curl
Here’s an example of a curl request, assuming a hypothetical endpoint and JSON format:
curl -X POST http://0.0.0.0:5000/complete \
-H "Content-Type: application/json" \
-d '{"text": "Once upon a time,", "top_p": 0.9, "top_k": 50, "temperature": 0.8, "length": 30}' http://localhost:5000/your_endpoint
Example response:
{
"completion":{
"generation_time":"0.8679995536804199s",
"text":["Once upon a time, the kingdom was ruled by a wise and just king..."]
}
}
Request/Response Objects
Request:
text: The input text (string).top_p: Probability for nucleus sampling (float).top_k: The number of top most probable tokens to consider (integer).temperature: Controls the randomness of the sampling process (float).length: The number of new tokens to generate (integer).
Response:
text: The generated text based on the input (string).generation_time: Time taken to generate the text (string, formatted as seconds).
Using Postman
- Set Up Postman: Download and install Postman from Postman’s official site.
- Send Request:
- Set the request type to
POST. - Enter the request URL:
[http://0.0.0.0:5000/complete](http://0.0.0.0:5000/complete.). - Navigate to the “Body” tab, select “raw” and “JSON (application/json)”.
- Enter the JSON payload:
{ "text": "Once upon a time,", "top_p": 0.9, "top_k": 50, "temperature": 0.8, "length": 30 }
- Click “Send” and view the API’s response in the section below.
Importing Curl to Postman
- Open Postman.
- Click “Import” > “Raw Text”.
- Paste your
curlrequest. - Click “Continue” and then “Import”.
Realizing Seamless Integration: Towards a Comprehensive Chat API
The flask application serves as an intermediate layer between the end-user and Llama 2, handling requests and responses efficiently. This allows developers to encapsulate interactions with Llama 2, ensuring that they can control, monitor, and potentially enhance the interaction flow as needed, presenting a well-structured, user-friendly API for various applications.
Conclusion: Pioneering Ahead with Llama 2
The future of chat applications beams brightly with the advent of models like Llama 2. Leveraging its power through an optimized Flask API paves the way for innovative applications and products, embedding nuanced, intelligent chat capabilities into myriad platforms.
This is a simplified and illustrative setup. In production, consider adding authentication, optimizing model loading (to avoid loading it with each request), and employing more advanced error handling and logging. For larger-scale applications, consider asynchronous frameworks like FastAPI, as they can handle concurrent requests more efficiently, especially when dealing with computationally intensive tasks like interacting with machine learning models.
Feel free to check out this sample GitHub repository for the full code and additional examples. This link is just a placeholder — you can create a repository and share your implementations!
Please note: Ensure to follow Meta’s use-case policy when implementing Llama in applications.
Now you can continue developing this application, enhancing, and scaling it based on specific use cases and requirements. If you have any specific section you’d like me to dive deeper into or if you’d like to continue, please let me know!
In our next segments, we will delve deeper into extending this basic API, exploring optimization, and scalability, and ensuring our API can cater to a plethora of user interactions seamlessly and efficiently. Stay tuned to navigate through the unfolding journey of AI chat applications with Llama 2!
GitHub Repository: Llama2-Flask-API
[1]: HuggingFace Open LLM leaderboard
[2]: Meta’s Llama 2 Announcement
[3]: Stability AI Release Notes for FreeWilly1 and FreeWilly2
Keep in touch: LinkedIn
Comments
Loading comments…